Data Management, Governance & AI Tools
Disclaimer and Limitations of Liability
Nature of This Report
This report has been prepared and published for general informational purposes. All assessments, characterizations, and statements regarding the strengths and weaknesses of tools, platforms, and vendors represent the independent professional opinions of the authors, formed on the basis of publicly available information as of the research date shown on the cover. They are expressions of opinion and analytical judgement, not statements of verified fact or objective measurement. Nothing in this report should be construed as a definitive evaluation of any product or organization.
Fair Comment and Editorial Independence
This report is published as independent research commentary. No vendor, product company, investor, or other commercial party has sponsored, funded, commissioned, or otherwise influenced its contents. No vendor was paid for inclusion, and no vendor received preferential treatment in exchange for any consideration. The authors have no financial interest in any of the tools or vendors assessed herein. Assessments reflect the authors' honest opinion based on available evidence and are made in good faith without malicious intent.
Accuracy and Currency
The data management and governance tools market evolves rapidly. Product capabilities, pricing, deployment models, ownership structures, and competitive positioning described in this report reflect information available at the research date. The authors make no warranty, express or implied, that this information is accurate, complete, or current at the time of reading. Capabilities and market positions may have changed materially since publication. Readers should independently verify all information directly with vendors before making any procurement, investment, or strategic decisions.
Right to Correct
Vendors or organizations who believe a specific factual statement in this report is materially inaccurate are invited to submit corrections with supporting evidence. The authors will review and, where warranted, publish a correction. This process does not apply to assessments of opinion or analytical judgement, which remain the sole prerogative of the authors.
No Advisory Relationship
This report does not constitute procurement advice, investment advice, legal advice, or any other form of professional advisory service. No reader should rely on this report as the sole or primary basis for any decision. The authors and their organization accept no liability for any loss, damage, or adverse outcome (direct, indirect, or consequential) arising from reliance on any content in this report.
Permitted Use
This report may be shared, cited, and quoted freely for non-commercial purposes provided the source is attributed and no content is altered or presented out of context. Use of excerpts in commercial procurement processes, vendor evaluations, or investor materials is permitted provided the full disclaimer is included or prominently referenced. The report may not be republished in full or in substantially modified form without prior written consent.
Trademarks
All product names, company names, logos, and trademarks referenced in this report are the property of their respective owners. Their use is solely for identification and commentary purposes and does not imply affiliation with or endorsement by those owners.
Executive Summary
The modern data ecosystem has expanded dramatically over the past decade, shifting from monolithic data warehouse architectures toward highly distributed, cloud-native platforms augmented by AI at every layer. Organizations face a complex matrix of tooling choices spanning data acquisition, movement, transformation, governance, quality, analytics, and intelligence.
This Element22 Research Report provides a structured analysis of 33 tool categories making up the contemporary data management and governance landscape. For each category the leading commercial and open-source products are identified, capabilities are assessed against modern requirements, and architectural considerations relevant to enterprise data strategy are highlighted.
Key Findings
The market is consolidating around a small number of cloud data platforms — principally Snowflake, Databricks, Google BigQuery, and Microsoft Fabric — each expanding horizontally to absorb adjacent tool categories. This consolidation is driven both by vendors seeking larger addressable markets and by enterprise clients wanting fewer integration points and simpler licensing structures.
Data governance, quality, and observability have matured from optional add-ons into first-class architectural requirements, pushed by regulatory pressure (GDPR, CCPA, HIPAA, DORA, EU AI Act) and the practical need for trustworthy AI training data.
Open table formats (Apache Iceberg, Delta Lake, Apache Hudi) are reshaping analytics storage, enabling multi-engine interoperability and dissolving the hard boundary between data lakes and data warehouses.
Unstructured data, accounting for 80–90% of enterprise data by volume, is finally receiving proper tooling attention. Document intelligence, content governance, and unstructured data cataloging have moved from niche requirements to mainstream priorities, particularly as organizations use LLMs to extract value from documents, emails, contracts, and media.
AI-native capabilities are embedded across every category. Auto-profiling, natural-language querying, intelligent pipeline generation, and anomaly detection are now expected features, not differentiators.
Agentic AI systems capable of autonomous multi-step data work are beginning to collapse traditional tool category boundaries, most notably in data preparation, discovery, lineage tracking, and orchestration.
The paper concludes with a forward-looking assessment of how large language models, foundation models, and agentic AI systems will reshape the data tooling landscape through 2030 and beyond, including the critical transition to real-time data architectures.
1. Introduction
1.1 The Evolving Data Landscape
Data has become the central strategic asset of the modern enterprise. Volume, velocity, and variety have grown exponentially, fueled by AI, cloud computing, IoT proliferation, digital commerce, and the ubiquity of SaaS applications. Regulatory requirements have simultaneously elevated data governance from a back-office discipline to a board-level priority.
The tooling ecosystem has gone through several waves of transformation. The first generation was dominated by on-premises relational databases and ETL tools from IBM, Oracle, Informatica, and SAP. The second brought the cloud data warehouse as an analytical hub, with Teradata, Netezza, and Amazon Redshift establishing columnar cloud storage. It was Snowflake, launched in 2012, that effectively closed this era rather than simply belonging to it. By fully separating storage from compute and delivering the warehouse as an elastic managed service, Snowflake made the architectural assumptions of the second generation look dated while most incumbents were still defending them. The third and current generation is defined by three concurrent forces: cloud-native managed services, the decentralization of data ownership through patterns like Data Mesh, and the rapid integration of artificial intelligence into every tier of the data stack. Snowflake has since expanded well beyond the warehouse into ingestion, transformation, governance, and AI, while its closest rival Databricks has converged from the opposite direction, moving from AI and machine learning toward governed analytics. The competition between the two, each trying to own the full data-to-AI lifecycle, is one of the defining dynamics of the current generation.
Two developments since 2023 have accelerated this evolution in ways that deserve particular attention.
First, AI is no longer an adjacent capability; it is becoming part of the data platform itself. Snowflake embeds Cortex AI directly in the warehouse. Databricks ships model training and inference alongside data engineering. BigQuery integrates Gemini for natural language querying and automated pipeline generation. Power BI Copilot turns dashboard creation into a conversation. Organizations evaluating tooling today need to assess AI readiness as a first-order criterion, not a bonus.
Second, the boundary between tool categories is dissolving. Vendors originally built for a single use case are systematically expanding into adjacent spaces. Collibra started as a governance tool and now competes in data catalog, lineage, quality, unstructured data governance and marketplace. Databricks started as a Spark runtime and now offers data lakehouse, catalog, governance, BI, and model deployment. The result is a market moving toward platform consolidation, where a smaller number of vendors cover a broader surface area. This creates both opportunity and risk for buyers: fewer tools and tighter integration on one side, deeper lock-in and feature-depth trade-offs on the other.
Unstructured data deserves specific mention as an area historically underserved by data management tooling built for structured tabular data. Documents, emails, contracts, call recordings, images, video, and social content collectively represent 80–90% of enterprise data by volume, yet most data governance, quality, and catalog tooling was built for relational tables. That gap is closing rapidly. Microsoft Purview now governs SharePoint, Exchange, and Teams content alongside SQL databases. BigID catalogs unstructured files alongside structured tables. Tools like AWS Textract, Google Document AI, Data Dynamics' Zubin and ABBYY Vantage extract structured information from documents at scale.
1.2 Reference Architecture
The diagram below illustrates the reference architecture for a modern enterprise data platform, showing how the major capability layers interact, from data sourcing and ingestion through engineering, governance, storage, and distribution to end consumers.
Figure 1 — Enterprise Data Platform Reference Architecture (Element22)
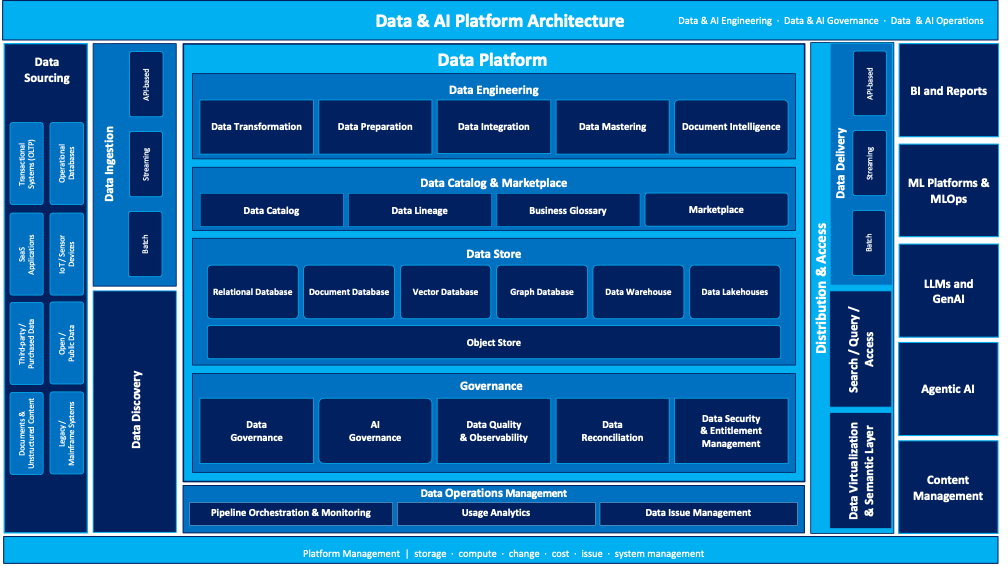
1.3 Purpose and Scope
This paper serves as a reference guide for data architects, Chief Data Officers, enterprise architects, and technology strategists. The scope covers 36 primary tool categories spanning the full data value chain from sourcing to intelligence, covering both commercial and open-source products with particular attention to cloud-native and multi-cloud deployments.
1.4 Research Methodology
Assessments draw on vendor documentation, analyst research (Gartner Magic Quadrant, Forrester Wave, IDC MarketScape), community adoption metrics (GitHub stars, Stack Overflow activity, CNCF landscape data), and practitioner feedback from the broader data engineering community as of Q1 2026. Tool capabilities are rated qualitatively across dimensions relevant to each category. Where a tool spans multiple categories, it is assessed in its primary category and referenced in others.
2. Tool Categories and Market Analysis
2.1 Data Sourcing
| Tool / Platform | Vendor | Deployment | Source Coverage | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Fivetran | Fivetran | SaaS / Cloud | 300+ pre-built connectors, fully managed CDC, automatic schema migration, dbt integration | No | 300+ connectors; gold standard for reliability; auto schema migration; dbt native | Pricing can be significant at scale; limited customization without custom connectors |
| Airbyte | Airbyte (OSS) | OSS / Cloud / Self-hosted | 400+ connectors (community + certified), connector dev kit (CDK), custom connectors | Yes | Largest open-source connector library; cost-effective; CDK allows rapid custom connectors | Community connectors vary in quality; managed cloud adds cost; less polished than Fivetran for enterprise |
| Stitch (Talend) | Talend / Qlik | SaaS | 100+ Singer-based connectors, simple SaaS, incremental replication | No | Simple and accessible; good for mid-market; Singer standard reduces lock-in | Roadmap uncertainty post-Qlik acquisition; limited connector depth; fewer features than Fivetran |
| Meltano | Meltano (OSS) | OSS / Self-hosted | Singer-compatible, GitOps-friendly, dbt and Airflow integration, CLI-first | Yes | GitOps-native; excellent code-first DX; integrates with dbt naturally | Self-managed; community support only; less suitable for non-technical teams |
| Hevo Data | Hevo Data | SaaS | 150+ sources, real-time streaming ingestion, built-in transforms, no-code | No | Good value; real-time ingestion; strong for Asia-Pacific market | Enterprise features still maturing; smaller connector library than Fivetran |
| Debezium | Red Hat (OSS) | OSS / Kafka | Log-based CDC for MySQL, Postgres, MongoDB, Oracle, SQL Server; Kafka Connector | Yes | Industry-standard open CDC; highly reliable; log-based means zero performance impact on source | Requires Kafka operational expertise; limited to CDC use case; no UI |
| Qlik Replicate (Attunity) | Qlik | On-prem / Cloud | CDC-focused, 40+ sources, real-time log-based replication, bidirectional | No | Mature CDC platform; strong enterprise pedigree; heterogeneous target support | Premium pricing; UI dated; requires specialist expertise |
| AWS Glue Connectors | AWS | Cloud (AWS) | JDBC/ODBC, Marketplace connectors, serverless crawlers, Spark-based | No (managed) | Serverless; deep AWS integration; S3, Redshift, RDS crawlers built-in | Connector coverage narrower than Fivetran; requires Spark knowledge for custom logic |
| Azure Data Factory Linked Services | Microsoft | Cloud (Azure) | 100+ connectors, integration runtime for on-prem hybrid, data flow transforms | No (managed) | Native Azure ecosystem; hybrid on-prem support via IR; strong enterprise support | UI complexity grows; Azure-centric; limited compared to Fivetran for SaaS connectors |
| Google Cloud Datastream | Cloud (GCP) | CDC from Oracle, MySQL, PostgreSQL, Spanner to BigQuery/GCS; serverless | No (managed) | Serverless; low-latency CDC into BigQuery; minimal configuration for GCP pipelines | Source coverage limited; BigQuery-centric; not suitable for multi-cloud targets | |
| Snowflake (as source) | Snowflake | Cloud (SaaS) | Snowflake Data Sharing, Dynamic Tables, Change Tracking for CDC from Snowflake tables | No | Zero-copy sharing; near-real-time change tracking; no ETL needed for downstream consumers | Source only; requires target system Snowflake connector; ecosystem dependent |
| Databricks (as source) | Databricks | Cloud (SaaS) | Delta Sharing (open protocol), Delta Change Data Feed, Unity Catalog data product sharing | Delta Sharing: Yes | Open Delta Sharing protocol works with any consumer; CDC via Change Data Feed; Unity Catalog governance | Source only; Delta Sharing consumer ecosystem still maturing vs. Snowflake marketplace |
| Apify / Diffbot | Apify / Diffbot | SaaS | Web scraping, public web data extraction, AI-powered entity extraction | Apify: Yes | Apify open-source actors; Diffbot AI entity extraction is unique; good for public web data pipelines | Not enterprise data sources; legal and rate-limit considerations; Diffbot cost can escalate |
Fivetran leads on connector breadth and managed reliability but faces pressure from Airbyte's open-source model at scale. Debezium remains the standard for production log-based CDC and is now complemented by Flink CDC for streaming use cases. Snowflake and Databricks as data sources are increasingly important: as organizations build data mesh architectures, these platforms are themselves producers of curated data products consumed by downstream systems via Delta Sharing or Snowflake Data Sharing. Cloud platform-native connectors (AWS Glue, Azure Data Factory, Datastream) continue gaining ground for organizations already committed to a single cloud.
2.2 Data Ingestion and Data Delivery
2.2.1 Batch Ingestion
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Apache Spark (batch) | Apache (OSS) | On-prem / Cloud | Distributed in-memory processing, Python/Scala/SQL/R APIs, Delta Lake integration, structured streaming | Yes | De facto standard for large-scale batch; rich ecosystem; Databricks removes ops overhead | High ops complexity without managed service; steep learning curve for custom connectors |
| AWS Glue (ETL) | AWS | Cloud (AWS) | Serverless Spark, visual Glue Studio, Glue Data Catalog integration, auto-scaling, Glue DQ | No (managed) | Serverless Spark; tight S3/Redshift/Athena integration; Glue DQ adds quality checks | Cost can escalate; Spark expertise still required for complex logic; AWS-only |
| Azure Data Factory | Microsoft | Cloud (Azure) | 100+ connectors, code-free data flows, integration runtime for on-prem, Fabric integration | No (managed) | Mature enterprise integration; hybrid on-prem support; strong governance via Purview | UI complexity grows; Spark-based data flows can be slow; largely AWS/GCP-ignored |
| Google Cloud Dataflow | Cloud (GCP) | Managed Apache Beam, unified batch/stream, autoscaling, BigQuery native integration | No (managed) | Serverless auto-scaling; BigQuery native; Beam portability across runtimes | Beam SDK adds abstraction overhead; debugging complex; GCP-centric | |
| Matillion ETL/ELT | Matillion | Cloud (SaaS) | Cloud DW-native ELT for Snowflake/BigQuery/Redshift/Databricks, visual builder, AI-assisted mapping | No | Visual pipeline builder; push-down execution uses DW compute efficiently; AI mapping | DW-centric; not suited to complex non-SQL transforms; per-connector licensing |
| Informatica IDMC | Informatica | Cloud / On-prem | Enterprise ETL/ELT, AI-powered mapping (CLAIRE), pushdown optimization, 500+ connectors | No | Broadest enterprise ETL; CLAIRE AI mapping saves time; strong hybrid support | Premium pricing; complex licensing; CLAIRE still requires human validation |
| IBM DataStage | IBM | On-prem / Cloud | Parallel processing ETL, deep IBM ecosystem, DataStage Next for cloud-native workloads | No | Mature parallel processing; strong in regulated industries; IBM Cloud modernization | Legacy architecture; slower cloud modernization vs. competitors; IBM lock-in risk |
| Talend Data Integration | Talend / Qlik | OSS / Cloud | GUI-based ETL, Java/Spark execution, 900+ components, DQ and governance integration | Yes (OSS Studio) | Large open-source community; extensive component library; DQ integration built-in | Qlik acquisition roadmap uncertainty; Java-heavy; licensing complexity growing |
| Snowflake (native ingestion) | Snowflake | Cloud (SaaS) | COPY INTO, Snowpipe (continuous), Dynamic Tables (declarative materialization), Streams | No | Near-zero latency with Snowpipe; Dynamic Tables replace complex ETL for many patterns; no extra cost | Snowflake-only; not suitable for multi-target ingestion; limited transformation logic vs. Spark |
| Databricks Auto Loader | Databricks | Cloud (SaaS) | Incremental file ingestion from cloud storage, schema inference, schema evolution, DLT integration | No | Seamless lakehouse ingestion; schema evolution built-in; tight Unity Catalog integration | Databricks-only; requires Delta Lake format; not suited for real-time streaming beyond micro-batch |
| Fivetran (ELT) | Fivetran | SaaS / Cloud | Managed ELT pipelines, 300+ source connectors, dbt integration for post-load transformation | No | Fully managed; reliable; excellent for SaaS-to-warehouse patterns; dbt native | Not a transformation engine; pricing at scale; connector-level billing model |
| dlt (data load tool) | dltHub (OSS) | OSS / Python | Python library for declarative pipelines, schema inference, incremental loading, Rust core | Yes | Lightweight; pure Python; great developer experience; fast growing community | Early stage; limited connector library vs. Fivetran; no managed service yet |
2.2.2 Streaming Ingestion
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Throughput / Latency | Operational Complexity |
|---|---|---|---|---|---|---|
| Apache Kafka | Apache / Confluent | OSS / Cloud | Distributed commit log, pub-sub, Kafka Connect ecosystem, Kafka Streams, 700+ connectors | Yes | Millions of msgs/sec; sub-10ms latency; massive ecosystem; battle-tested at hyperscale | Operational complexity (ZooKeeper historically); rebalancing events; requires Kafka expertise to tune |
| Confluent Platform / Cloud | Confluent | Cloud / On-prem | Managed Kafka, Schema Registry, ksqlDB, Connectors, RBAC, FLINK integration, audit logs | Partial (OSS Kafka) | Reduces Kafka ops dramatically; Schema Registry prevents breaking changes; enterprise RBAC | Premium pricing; vendor lock-in risk beyond OSS Kafka; BYOC model needed for regulated industries |
| Apache Flink | Apache (OSS) | On-prem / Cloud | Stateful stream processing, event time semantics, Flink SQL, Flink CDC (source replacement) | Yes | Best stateful streaming; event-time correctness; Flink CDC excellent for DB-to-stream | Operational complexity; JVM tuning; state backend management; steep learning curve |
| AWS Kinesis | AWS | Cloud (AWS) | Data Streams, Firehose (delivery to S3/Redshift), Analytics (Flink-based); fully managed | No | Fully managed; pay-per-use; Firehose zero-ETL to S3/Redshift; Amazon Q integration | AWS-only; Shard management complexity; limited to 7-day retention; harder to tune vs. Kafka |
| Azure Event Hubs | Microsoft | Cloud (Azure) | Kafka-compatible, Stream Analytics (SQL-based), Capture to ADLS, Fabric Real-Time Intelligence | No | Kafka wire compatibility; Fabric RTI makes streaming first-class; minimal migration from Kafka | Kafka compatibility partial; Stream Analytics SQL is limited vs. Flink; Azure-only |
| Google Pub/Sub + Dataflow | Cloud (GCP) | Pub/Sub messaging plus Dataflow (Beam) for stream processing; BigQuery direct streaming | No | Globally distributed; auto-scales to zero; Dataflow exactly-once into BigQuery | Beam SDK complexity; GCP-centric; Pub/Sub ordering guarantees limited vs. Kafka partitions | |
| Apache Pulsar | Apache (OSS) | OSS / StreamNative Cloud | Multi-tenancy, tiered storage, geo-replication, Kafka compatibility layer, functions | Yes | Native tiered storage; strong multi-tenancy; Kafka wire compatible; geo-replication built-in | Smaller ecosystem than Kafka; tooling maturity behind; StreamNative adds cost |
| Redpanda | Redpanda | OSS / Cloud | Kafka-compatible C++ core, no ZooKeeper, very low latency, simple operations, WarpSpeed | Yes | Best p99 latency; 10x fewer nodes than Kafka for same throughput; operational simplicity | Smaller ecosystem than Kafka; enterprise features still maturing; not Kafka 100% feature parity |
| Snowflake Dynamic Tables | Snowflake | Cloud (SaaS) | Declarative streaming/micro-batch materialization, change propagation, freshness targets, DML-based CDC | No | Zero operational overhead; SQL-only; replaces many streaming ETL patterns inside Snowflake | Latency higher than true streaming (minutes); Snowflake-only; SQL transforms only |
| Databricks Structured Streaming | Databricks | Cloud (SaaS) | Spark Structured Streaming, DLT continuous mode, Delta Live Tables, Kafka/Kinesis/Pub-Sub connectors | Spark: Yes | Unified batch/stream in one framework; DLT adds quality and monitoring; excellent Delta Lake integration | Databricks-only for managed; micro-batch model (not true event-driven); higher latency than Flink |
| Google BigQuery Streaming (Storage Write API) | Cloud (GCP) | Native streaming inserts to BigQuery, Storage Write API (committed/buffered/pending modes), exactly-once | No | Sub-second data freshness in BigQuery; exactly-once semantics; no separate streaming infrastructure | BigQuery-only; no intermediate stream processing; requires separate stream processor for transforms |
2.2.3 API-Based Ingestion
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| MuleSoft Anypoint Platform | Salesforce | Cloud / On-prem | API-led connectivity, 500+ connectors, DataWeave transforms, API management, MQ messaging | No | Most comprehensive iPaaS; API management included; Einstein AI mapping assistance; huge connector library | Premium pricing; complex licensing; steep learning curve; heavy for simple use cases |
| Dell Boomi | Boomi | Cloud (SaaS) | iPaaS, 1600+ connectors, MDM, API Management, Flow workflow engine, Boomi AI mapping | No | Largest connector count; Boomi AI reduces mapping time significantly; strong mid-enterprise fit | Less deep API management vs. MuleSoft; some connectors are thin wrappers; cloud-only |
| Workato | Workato | Cloud (SaaS) | Enterprise automation and integration, 1000+ connectors, recipe-based, AI Copilot, API platform | No | Business user accessible; fastest time-to-value for SaaS integration; AI Copilot helpful | Less suited for complex data engineering; limited transformation depth vs. MuleSoft |
| AWS API Gateway + Lambda | AWS | Cloud (AWS) | Custom API ingestion, serverless, event-driven, Step Functions orchestration, EventBridge | No | Infinitely flexible; pay-per-use serverless; tight AWS data service integration | Requires custom code; no pre-built connectors; dev and ops overhead |
| Azure API Management + Logic Apps | Microsoft | Cloud (Azure) | API gateway with policies, Logic Apps for workflow automation, 400+ connectors, Fabric event-driven triggers | No | Deep Azure ecosystem; Logic Apps no-code connectors; APIM handles authentication, throttling, transformation | Logic Apps JSON config verbose; APIM learning curve; Azure-centric; Logic Apps pricing complexity |
| Azure Event Grid + Functions | Microsoft | Cloud (Azure) | Event-driven ingestion, 25+ event sources, serverless Functions, push-based delivery to 20+ handlers | No | Native Azure event routing; near-real-time push delivery; deeply integrated with Azure Data Factory and Fabric | Azure-only; limited transformation; event schema management required externally |
| Apigee (Google) | Cloud (GCP) | Full API management, analytics, developer portal, hybrid gateway, Advanced API Security | No | Best API analytics in market; hybrid deployment; strong monetization and developer portal | Heavy for simple use cases; GCP-centric; pricing per API call can escalate | |
| Celigo | Celigo | Cloud (SaaS) | iPaaS for SaaS integration, pre-built integration apps, FlowBuilder, ERP and CRM connectors, AI mapping | No | Pre-built ERP/CRM integration apps save weeks; AI field mapping; strong NetSuite specialization | Narrower than Boomi/MuleSoft; less suitable for complex data pipelines; SaaS integration focus |
Modern ingestion architectures favor Lambda or Kappa patterns, handling batch and streaming through a common metadata layer. The shift to cloud-native, push-down ELT using the warehouse's own compute has disrupted traditional ETL vendors. Apache Kafka remains the dominant streaming backbone, with Confluent leading the managed space, while Redpanda challenges with C++ performance and operational simplicity.
The significant 2025–2026 development is the native streaming ingestion capabilities from Snowflake (Snowpipe, Dynamic Tables), Databricks (Auto Loader, Structured Streaming), and Google (BigQuery Storage Write API): for teams already on these platforms, separate ingestion tooling is increasingly optional. Enterprise requirements consistently include exactly-once semantics, schema evolution support, end-to-end lineage, and native governance integration.
Data delivery leverages the same connectors, messaging platforms, and streaming infrastructure as ingestion. Snowflake Data Marketplace and Databricks Marketplace extend this to commercial and cross-organization data product distribution, enabling zero-copy data delivery at scale without physical data movement.
2.3 Data Discovery
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Alation Data Intelligence | Alation | Cloud / On-prem | AI-powered search, behavioral analytics, stewardship workflows, SQL editor, query history mining, file system asset coverage | No | Pioneer in ML-powered discovery; strong behavioral analytics surface curation priorities automatically; extending to files and documents | Primarily structured data strength; unstructured coverage still maturing; complex implementation for large estates |
| Atlan | Atlan | Cloud (SaaS) | Collaboration-focused discovery, 50+ integrations, lineage, policies, AI search, embedded glossary, Slack/Teams integration | No | Modern developer-friendly UX; fast-growing; strong OpenMetadata standards support; excellent API extensibility | Newer vendor; enterprise breadth still maturing compared to Collibra and Alation; primarily structured data focus |
| Collibra Data Intelligence Cloud | Collibra | Cloud / On-prem | Enterprise catalog, business glossary, lineage, governance workflows, data marketplace, document assets via Collibra DeasyLabs | No | Market leader; comprehensive structured coverage; document and unstructured data discovery through DeasyLabs integration | High implementation cost and complexity; requires significant ongoing stewardship effort; premium pricing |
| Collibra DeasyLabs | Collibra | Cloud (SaaS) | Unstructured data discovery and classification, AI-powered document metadata extraction, SharePoint/S3/NAS scanning, sensitive data identification in documents | No | Purpose-built for unstructured discovery within Collibra ecosystem; AI-driven metadata extraction; strong compliance use cases | Collibra ecosystem dependency; newer product still building enterprise references; primarily document and file focus |
| DataHub | LinkedIn / Acryl Data | OSS / Cloud (Acryl) | Metadata platform, push/pull ingestion, lineage, search, column-level lineage, custom entities for any asset type | Yes (Apache 2.0) | Leading OSS metadata platform; 9k+ GitHub stars; highly extensible; custom entity model supports unstructured assets | Requires engineering resource to operate OSS version; UI less polished than commercial tools; professional services needed at scale |
| Microsoft Purview | Microsoft | Cloud (Azure) | Automated scanning of Azure SQL, Blob, ADLS, SharePoint, Exchange, Teams, sensitivity labels, classification, M365 data map | No | Strongest unstructured data discovery in market; unique M365 coverage; good structured DW coverage growing rapidly | Azure/M365 ecosystem dependency; non-Microsoft source coverage less deep; governance workflows less mature than Collibra |
| Google Dataplex / Data Catalog | Cloud (GCP) | Unified data management, auto-discovery of GCS objects and BigQuery, tagging, data quality rules, lineage, GCS object coverage | No | Native GCP integration; GCS object discovery covers unstructured file assets; strong BigQuery lineage | GCP-centric; limited coverage outside Google Cloud; business metadata and governance capabilities less mature than specialist tools | |
| AWS Glue Data Catalog | AWS | Cloud (AWS) | Central metadata repository, crawler-based discovery of S3 and JDBC sources, Lake Formation integration, S3 object discovery | No | Foundational AWS data discovery; S3 crawlers discover unstructured file assets; tightly integrated with AWS analytics services | Limited business metadata and search quality; no governance workflow; primarily technical metadata focus |
| BigID | BigID | Cloud (SaaS) | Data discovery across 500+ structured and unstructured sources including S3, SharePoint, NAS, databases; PII identification, classification, data risk scoring | No | Leader for unstructured data discovery; finds sensitive data in files, emails, and cloud storage regardless of format; very broad source coverage | Primarily a security/privacy tool rather than analytics discovery; catalog and lineage features less mature than pure catalog vendors |
| Data Dynamics Zubin | Data Dynamics | Cloud / On-prem | Unstructured data discovery across NAS, S3, SharePoint, file servers; content classification, metadata extraction, compliance identification, storage tiering | No | Strong focus on unstructured data governance and discovery; storage cost optimisation alongside compliance; good for file-heavy organizations | Less known in the market than BigID or Purview; primarily unstructured focus; structured data capabilities limited |
| Ohalo | Ohalo | Cloud (SaaS) | AI-powered unstructured data discovery, semantic search over file stores, auto-classification, GDPR/CCPA compliance discovery across documents and emails | No | Purpose-built for unstructured data compliance; strong semantic AI search; identifies personal data in complex document layouts | Smaller vendor; primarily compliance-driven use case; less suitable as a general-purpose discovery platform |
| Clarista | Clarista | Cloud (SaaS) | AI-native data discovery and analytics, natural language search over business data, automatic insight generation, self-service exploration for non-technical users | No | Excellent natural language query experience; lowers barrier for non-technical discovery; rapid deployment; modern LLM-powered interface | Newer entrant; enterprise governance depth still maturing; best suited for analytics discovery rather than compliance or lineage use cases |
| Elasticsearch / OpenSearch | Elastic / AWS | Cloud / OSS | Full-text search over unstructured and semi-structured content, vector search, NLP-based content discovery, multi-tenant indices | Yes (OpenSearch) | Essential for free-text and semantic search over documents and logs; vector search capability is strong for RAG architectures | Not a metadata catalog; requires engineering to build governance layer; no lineage or stewardship workflow out of the box |
| Secoda | Secoda | Cloud (SaaS) | AI-native discovery, natural language search, automated documentation, Slack/Teams integration, LLM-powered metadata generation | No | Modern AI-first approach; LLM-powered search and documentation; good for teams wanting low-friction discovery with minimal curation overhead | Smaller vendor; enterprise governance breadth limited; primarily structured data; less suitable for complex unstructured estates |
Data discovery is converging with catalog functionality, and the sharpest competitive differentiator today is unstructured data coverage. Microsoft Purview is notably ahead in discovering and classifying M365 content alongside structured databases. BigID leads for breadth across heterogeneous file types. Data Dynamics Zubin and Ohalo serve organizations where the primary concern is governance of file server and cloud object store content rather than database metadata.
Clarista represents a new wave of AI-native discovery tools that prioritize the end-user experience over governance depth, making analytics discovery far more accessible to non-technical stakeholders. For enterprise programs, the most capable organizations combine a structured data catalog such as Alation or Atlan with an unstructured discovery tool, rather than expecting one platform to cover everything equally well. OpenMetadata and OpenLineage standards are reducing lock-in risk on the structured side as the ecosystem matures.
2.4 Data Platform
2.4.1 Data Engineering
Data engineering encompasses all tooling that transforms, prepares, integrates, and masters data within the platform. It covers the compute-intensive work of turning raw ingested data into analytical-ready and ML-ready datasets, as well as the specialized work of establishing master records for critical business entities. Document management is included here as the engineering discipline responsible for processing, classifying, and routing document content as a structured asset within the pipeline.
2.4.1.1 Data Transformation (Pipelines)
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| dbt (data build tool) | Fivetran | OSS / dbt Cloud | SQL-based transformations, modular DAGs, testing, documentation, version control, Semantic Layer, column-level lineage | Yes | De facto ELT standard; 30k+ GitHub stars; version-controlled; column-level lineage from v1.6; semantic layer | SQL-only without add-ons; limited support for complex non-SQL logic; dbt Cloud adds cost |
| Apache Spark | Apache (OSS) | On-prem / Cloud | Distributed transforms, Python/Scala/SQL/R APIs, MLlib, structured streaming, Delta Lake | Yes | Essential for large-scale or complex transforms; supports ML pipelines; Databricks removes ops overhead | Steep learning curve; overkill for simple transforms; Java/Scala debugging complex |
| Snowflake (Snowpark) | Snowflake | Cloud (SaaS) | Python/Java/Scala transforms inside Snowflake, DataFrame API, stored procedures, Dynamic Tables, ML functions | No | Pushdown transforms in Snowflake compute; no data movement; supports Python pandas-like syntax | Snowflake-only; limited to Snowflake ecosystem; Python support newer and still maturing |
| Databricks Delta Live Tables | Databricks | Cloud (Databricks) | Declarative pipeline framework on Spark, DLT expectations, auto-scaling, Unity Catalog integration, Python/SQL | No | Asset-oriented transforms; quality expectations built-in; Unity Catalog integration; continuous and triggered modes | Databricks-only; opinionated framework; debugging more complex than standard notebooks |
| AWS Glue (ETL) | AWS | Cloud (AWS) | Serverless Spark, visual Glue Studio, Glue Data Catalog, Glue Data Quality, Python/Scala | No | Serverless; AWS-native; Glue DQ adds quality checks; visual authoring for non-engineers | Spark expertise required for complex transforms; cost can escalate; AWS-only ecosystem |
| Google Cloud Dataflow (Beam) | Cloud (GCP) | Unified batch/stream transforms via Apache Beam SDK, autoscaling, BigQuery direct write | No | True unified batch/stream; portable to Flink/Spark runners; BigQuery native; serverless | Beam abstraction adds complexity; debugging hard; GCP-centric; steeper learning curve | |
| Matillion ETL/ELT | Matillion | Cloud (SaaS) | Cloud DW-native ELT for Snowflake/BigQuery/Redshift/Databricks, visual builder, AI-assisted column mapping | No | Visual pipeline builder with SQL pushdown; AI mapping accelerates development; good governance hooks | DW-centric; Python components exist but feel bolted on; per-connector licensing |
| Coalesce | Coalesce | Cloud (SaaS) | SQL-first visual ELT for Snowflake, column-aware transforms, documentation, dbt export capability | No | Innovative visual-to-SQL; column-level lineage built-in; excellent Snowflake integration | Snowflake-only currently; growing but smaller community than dbt; newer platform |
| Informatica IDMC (transforms) | Informatica | Cloud / On-prem | Complex transforms, AI-assisted mapping (CLAIRE), pushdown optimisation, MDM integration, data quality | No | Enterprise-grade; CLAIRE AI mapping reduces effort; supports complex multi-source transforms | Premium pricing; complex licensing; CLAIRE still needs human oversight |
| Talend Open Studio | Talend / Qlik | OSS / Cloud | GUI ETL, Java/Spark execution, 900+ components, DQ and governance integration | Yes (Studio) | Open-source community edition; extensive component library; DQ integration baked in | Qlik acquisition uncertainty; Java execution environment heavy; OSS version falling behind |
| Trino / Starburst | Trino (OSS) / Starburst | On-prem / Cloud | Federated SQL query engine, push-down to heterogeneous sources, Iceberg/Hudi/Delta support, ANSI SQL | Yes (Trino) | Federated transforms across multiple stores without data movement; excellent Iceberg support | Not a transform orchestration tool; no pipeline scheduling; complex tuning for performance |
| Ab Initio | Ab Initio Software | On-prem / Cloud | Parallel batch transformation, graphical component-based development (GDE), high-volume data processing, complex joins and aggregations, Co>Operating System for job scheduling, metadata hub, data profiling | No | Unmatched throughput for very large batch workloads; proven at the largest financial institutions for core processing; highly reliable for mission-critical overnight batch; strong parallelism model handles complex multi-source transformations well | Proprietary and closed; pricing is opaque and significant; no cloud-native deployment model; requires specialist Ab Initio skills that are increasingly scarce; poor fit for modern ELT patterns and real-time pipelines; no community or open-source ecosystem |
The transformation landscape has bifurcated. For warehouse-centric analytics, dbt has become the community standard. For large-scale distributed processing, Apache Spark via Databricks, AWS EMR, or Google Dataproc remains the engine of choice. The platform-native transformation services from Snowflake (Snowpark), Databricks (DLT), and AWS (Glue) are increasingly good enough for teams already committed to those platforms, reducing the case for separate transformation tools.
Column-level lineage natively within transformation definitions (dbt 1.6+, DLT), semantic layer support for consistent metric definitions, and incremental/CDC-aware patterns for near-real-time analytics are the modern requirements most organizations still need to fully implement.
2.4.1.2 Data Preparation
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Alteryx Designer / Cloud | Alteryx | Desktop / Cloud | Visual drag-and-drop data prep, 80+ transform tools, predictive analytics, spatial analytics, AI-assisted wrangling, document parsing via Alteryx AI Platform | Partial (Community) | Market leader for business analysts; widest range of built-in connectors; AI-assisted suggestions; strong document processing | Per-seat licensing is expensive; cloud migration still maturing; heavy desktop client for advanced workflows |
| Dataiku DSS | Dataiku | On-prem / Cloud | End-to-end data science platform, visual recipes, Spark/SQL execution, collaborative notebooks, LLM recipe support for unstructured data | Partial (free tier) | Bridges data prep and ML in one platform; strong governance and collaboration features; good unstructured handling via LLM recipes | Broad scope can feel overwhelming; enterprise pricing is significant; full value requires team-wide adoption |
| Google Cloud Dataprep (Trifacta) | Google / Trifacta | Cloud (GCP) | ML-based anomaly detection, intelligent transform suggestions, visual wrangling, BigQuery integration, pipeline publishing | No | Excellent ML-driven suggestions; deep BigQuery/GCS integration; low operational overhead as managed service | Primarily structured/tabular focus; GCP-centric; less suitable outside Google ecosystem; acquired product with evolving roadmap |
| Microsoft Power Query / Dataflows | Microsoft | Cloud / Desktop | M language transforms, Power BI/Fabric integration, 1000+ connectors, AI column suggestions, incremental refresh, Dataflows Gen2 | No | Ubiquitous in Microsoft ecosystem; excellent accessibility for business analysts; Fabric Dataflows Gen2 adds enterprise scale | M language has a learning curve; performance constraints at very large volumes; best value inside Microsoft stack |
| Talend Data Preparation | Talend / Qlik | Cloud / On-prem | Collaborative wrangling, shared recipes, data quality rules integration, semantic discovery, profiling | No | Good governance integration within Talend suite; shared recipe library promotes team reuse; strong DQ integration | Qlik acquisition creates some roadmap uncertainty; less compelling outside the Talend suite; UI less modern than peers |
| OpenRefine | OSS (community) | Desktop / OSS | Free open-source wrangling, clustering algorithms, GREL expressions, Wikidata reconciliation, faceted browsing | Yes | Completely free; powerful clustering for dirty categorical data; widely used in journalism and research; active community | Not suited to enterprise scale or automation; desktop-only; no collaboration; limited structured pipeline integration |
| Ab Initio | Ab Initio Software | On-prem / Cloud | High-performance parallel data processing, graphical data prep flows, complex transformations, metadata management, enterprise-grade lineage | No | Exceptional throughput for very large batch volumes; deep metadata and lineage capabilities; strong in financial services | Very high licensing cost; steep learning curve; limited cloud-native deployment options; requires specialist skills |
| Snowflake (Snowpark / Worksheets) | Snowflake | Cloud (SaaS) | Snowpark Python/Java/Scala data prep inside the warehouse, DataFrame API, vectorised UDFs, notebook workflows, AI/ML functions | No | Eliminates data movement for prep; unified compute and storage; strong scalability; ML functions run in-warehouse | Requires Snowflake as the data platform; Python proficiency needed; limited visual/no-code interface for business users |
| Databricks AutoML / Feature Store | Databricks | Cloud | Automated feature engineering, feature reuse, MLflow integration, Unity Catalog governance, text feature support | Partial (MLflow OSS) | Tightly integrated prep for ML workflows; good for mixed structured and unstructured data; strong for teams building models | Primarily ML-oriented rather than general prep; requires Databricks platform; limited business-user tooling |
| SAS Data Management | SAS | On-prem / Cloud | Data prep, quality, profiling; deep statistical integration; SAS Viya cloud modernization; federation and virtualisation | No | Very strong in regulated industries; SAS Viya modernization underway; deep statistical and analytical integration | Legacy architecture and pricing model; cloud migration slower than competitors; high total cost of ownership |
| ABBYY Vantage | ABBYY | Cloud / On-prem | Document AI, intelligent document processing, OCR, field extraction, table recognition, unstructured to structured conversion | No | Leader in document prep; critical for invoice/contract/form processing at scale; high OCR accuracy; strong NLP field extraction | Primarily document-oriented; limited tabular data prep capability; integration effort required for data pipeline use |
| AWS Textract | AWS | Cloud (AWS) | ML-powered OCR, forms and table extraction, signature detection, queries API for targeted field extraction, S3 and Lambda integration | No | Highly accessible managed document prep; excellent AWS integration; pay-per-use pricing; strong API for pipeline automation | AWS-centric; limited business-user tooling; table extraction can struggle with complex layouts; cost scales with volume |
Modern data preparation tools increasingly need to serve two audiences: data engineers requiring scalable, automated transformation pipelines, and business analysts needing intuitive visual tools. The shift toward cloud-native in-warehouse preparation using Snowpark or Databricks is reducing reliance on standalone prep tools for technical users, but visual tools like Alteryx and Power Query retain strong adoption among non-engineers. Ab Initio fills a specific high-performance niche for organizations processing extremely large batch volumes where throughput is non-negotiable.
The most significant recent change is the formal inclusion of document preparation. ABBYY Vantage and AWS Textract now sit naturally alongside Alteryx and Dataiku in the preparation layer, converting contracts, invoices, and forms into structured datasets ready for analytics or AI training.
2.4.1.3 Data Integration
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| MuleSoft Anypoint Platform | Salesforce | Cloud / On-prem | API-led connectivity, 500+ connectors, DataWeave transformation language, API management gateway, MQ messaging, Composer no-code option, Copilot AI for mapping | No | Gartner MQ leader; comprehensive API plus integration platform; very strong connector ecosystem; Einstein/Copilot AI accelerates integration development significantly | Premium pricing that makes it primarily enterprise territory; DataWeave learning curve; best value when full platform is adopted rather than used selectively |
| Azure API Management + Logic Apps | Microsoft | Cloud (Azure) | Enterprise API gateway, developer portal, OAuth2/OIDC security, policy engine, Logic Apps for event-driven workflow integration, Azure Functions for custom connectors, Event Grid for event routing | No | Comprehensive Azure-native API management plus integration; Event Grid enables event-driven data integration at scale; deep Microsoft ecosystem integration; strong RBAC and security policy engine | Azure-centric; cross-cloud API management less capable than MuleSoft; Logic Apps pricing can escalate; complex scenarios require Azure Functions custom code |
| AWS API Gateway + EventBridge | AWS | Cloud (AWS) | Managed REST/WebSocket/HTTP API gateway, Lambda integration, EventBridge event bus for application and SaaS event routing, Step Functions for workflow orchestration, 200+ SaaS event sources | No | Powerful serverless API and event-driven integration on AWS; EventBridge connects 200+ SaaS applications natively; strong for event-driven data integration architectures; pay-per-use model | AWS-centric; enterprise API management capabilities less mature than MuleSoft or Azure APIM; cross-cloud orchestration requires custom work |
| Informatica IDMC | Informatica | Cloud (SaaS) | Unified cloud data management platform, ETL/ELT, MDM, DQ, API services, CLAIRE AI engine, 500+ connectors, document processing pipelines | No | Broadest enterprise data integration platform; AI-assisted mapping via CLAIRE is genuinely impressive; premium pricing but genuinely comprehensive depth across ETL, API, MDM, and DQ | High cost; best value when adopting the full platform; complex deployment; API management capabilities less mature than MuleSoft |
| Dell Boomi AtomSphere | Boomi | Cloud (SaaS) | iPaaS, 1600+ connectors, MDM, API Management, Flow workflow engine, Boomi AI for mapping and integration suggestions, event-driven integration | No | Largest connector ecosystem in the iPaaS market; strong mid-to-large enterprise adoption; Boomi AI accelerates configuration time substantially; good balance of capability and usability | Less deep for API management than MuleSoft; AI capabilities still maturing; complex processes require professional services; pricing has increased significantly |
| Azure Data Factory / Fabric | Microsoft | Cloud (Azure) | Cloud ETL/ELT, 100+ connectors, SSIS migration pathway, data flows, pipeline monitoring, Mapping Data Flows, Fabric Data Factory integration, Copilot assistance | No | Strong Microsoft-ecosystem data integration; Fabric Data Factory is the strategic direction; mature monitoring and alerting; Copilot AI simplifies pipeline building for common patterns | Azure-centric; less comprehensive iPaaS than MuleSoft or Boomi; no native API management; complex transformation requires custom Spark code |
| AWS Glue + Step Functions | AWS | Cloud (AWS) | Serverless ETL (Glue Spark and Python Shell), Glue Data Quality, Glue Catalog, Step Functions workflow orchestration, Lambda for custom logic, event-driven triggers | No | AWS-native serverless integration; strong serverless model eliminates cluster management; Glue Data Quality adds inline quality checks; pay-per-use cost model | Custom code required for complex transformation logic; limited visual development experience; integration logic can become hard to govern without good practices |
| Talend Data Fabric | Talend / Qlik | Cloud / On-prem | Unified data integration, ETL, API, DQ, catalog, and governance in one platform; Qlik Analytics integration creating combined analytics and integration story | Partial (Talend Open Studio OSS) | Comprehensive platform; open-source edition available for evaluation; Qlik integration adds analytics context; good regulatory compliance documentation | Qlik acquisition creating some roadmap uncertainty; UI less modern than newer tools; cloud-native features building on older architecture |
| Workato | Workato | Cloud (SaaS) | Enterprise automation and integration, 1000+ connectors, low-code recipe builder, API platform, AI Copilot for recipe generation, real-time triggers | No | Fast-growing at the business automation and integration convergence; excellent user experience for non-engineers; AI Copilot for recipe generation is practical and saves significant time | Less deep for heavy data engineering integration than Informatica or Boomi; primarily business process integration focus; large data volumes can be costly |
| Airbyte + dbt (ELT stack) | Airbyte + dbt Labs (OSS) | OSS / Cloud | Open-source ELT: Airbyte for extraction and loading (300+ connectors), dbt for SQL transformation, Git-managed, community connector ecosystem | Yes (MIT / Apache 2.0) | Modern cost-effective OSS integration stack; 300+ source connectors in Airbyte; vibrant community; Git-native workflow; Airbyte Cloud adds managed service option | Less enterprise feature depth than Informatica or MuleSoft; custom connectors require engineering; data quality and governance require additional tooling beyond the base stack |
Enterprise data integration is converging with application integration and API management. Classical ETL tooling is being absorbed by ELT approaches for analytical use cases, while iPaaS platforms expand to cover data integration scenarios. AI-assisted connector configuration and field mapping is now a real differentiator: Boomi AI and CLAIRE in Informatica both reduce integration configuration time significantly for standard patterns. Event-driven integration patterns are growing alongside batch, reflecting the broader push toward real-time data operations.
2.4.1.4 Data Mastering (Master Data Management)
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Informatica MDM (IDMC) | Informatica | Cloud / On-prem | Customer/supplier/product MDM, hierarchy management, match-merge with survivorship rules, CLAIRE AI entity resolution, real-time MDM APIs | No | Gartner leader; comprehensive multi-domain MDM; CLAIRE ML matching strong and continuously improving; real-time APIs for operational MDM use cases; deepest feature set in market | High cost and implementation complexity; best value inside Informatica ecosystem; implementation projects require significant time and specialist expertise |
| Reltio Connected Data Platform | Reltio | Cloud (SaaS) | Cloud-native MDM, knowledge graph-based entity resolution, real-time APIs, Reltio AI, multi-domain support, continuous intelligence | No | Modern cloud-native challenger with ML-native matching; strong API-first architecture; knowledge graph approach handles complex relationships; growing enterprise adoption | Newer vendor building enterprise references; implementation effort still significant; deep customization can be complex; primarily strong in customer MDM |
| Stibo Systems STEP | Stibo Systems | On-prem / Cloud | Multi-domain MDM, product and supplier MDM, digital asset management, PIM combined with MDM, workflow automation, GDSN connectivity | No | Strong in product and supplier domains; comprehensive PIM plus MDM is unique; large enterprise focus; GDSN for retail supply chain is a differentiator | UI less modern than cloud-native peers; primarily product data focus; implementation projects lengthy; less strong in customer MDM compared to Informatica |
| EnterWorks (Syndigo) | Syndigo (EnterWorks) | Cloud (SaaS) | Product information management and MDM, content syndication, digital asset management, channel-specific data publishing, retailer and distributor connectivity | No | Strong product MDM with content syndication; excellent for consumer goods and retail where channel-specific product data distribution is critical; Syndigo network connects to retailers directly | Primarily product MDM and PIM; customer or supplier MDM less capable; primarily consumer goods and retail vertical focus |
| GoldenSource | GoldenSource | Cloud / On-prem | Financial instrument master data, security reference data management, corporate actions, entity (LEI) management, regulatory reporting integration, real-time data distribution | No | Specialist in financial instrument and security reference data; deep capital markets domain knowledge; strong regulatory data management for MiFID II, EMIR, FRTB; proven at global banks | Financial services specialist; not suitable as general-purpose enterprise MDM; high implementation cost; primarily tier-one financial institution focus |
| Gresham Alveo | Gresham Technologies | Cloud / On-prem | Financial data management platform, reference data, pricing, corporate actions, static data governance, data distribution to downstream systems, data quality controls | No | Comprehensive financial data management for capital markets; strong data distribution and feed management capability; good reference data governance; proven in buy-side and sell-side | Financial services specialist; not a general-purpose MDM platform; Gresham primarily known for reconciliation; Alveo market presence building |
| EDM (Gresham) | Gresham Technologies | Cloud / On-prem | Enterprise data management for financial services, instrument data, pricing, valuations, entity data, regulatory data management, data quality and lineage | No | Comprehensive financial EDM from a market data leader; strong instrument data and pricing management; well-established tier-one bank deployments | Gresham strategic direction post acquisition from S&P still clarifying; primarily financial services; high implementation and licensing cost |
| SAP Master Data Governance | SAP | On-prem / Cloud (Rise) | ERP-native MDM, governance workflows, S/4HANA consolidation, Finance/Business Partner/Material domains, central governance hub | No | Essential for SAP-centric enterprises; very deep S/4HANA alignment; governance workflows tightly integrated with ERP processes; Finance and Business Partner domains are very strong | Limited value outside SAP ecosystem; less flexible for non-SAP data; cloud deployment still maturing; tightly coupled to SAP release cycle |
| Semarchy xDM | Semarchy | Cloud / On-prem | Agile multi-domain MDM, graphical data model design, low-code application development, embedded DQ, intelligent matching and merge | No | Strong model-driven agile delivery; good for organizations wanting faster MDM implementation than legacy platforms; growing mid-market adoption; reasonable total cost of ownership | Smaller vendor with more limited global implementation partner network; enterprise-scale references building; less deep for very complex financial or product hierarchies |
| Ataccama ONE (MDM) | Ataccama | Cloud / On-prem | AI-powered MDM, automated profiling, ML match-merge, unified DQ and MDM platform, self-service stewardship workflows, European deployment options | No | Unique DQ plus MDM combination reduces platform count; strong AI-first approach with active learning; European vendor with good EU data residency options; growing enterprise adoption | Less known than Informatica or IBM in large enterprise; full value requires MDM and DQ adoption together; financial services domain depth less established |
| Tamr | Tamr | Cloud (SaaS) | ML-powered entity resolution at scale, customer and supplier MDM, active learning from stewardship feedback, Snowflake and Databricks native integration | No | Modern ML-native approach with genuinely fast implementation versus legacy MDM; active learning improves matching with every stewardship decision; strong for complex matching scenarios | Newer vendor; governance workflow depth building; best for matching-intensive use cases; less comprehensive for hierarchy management and multi-domain governance than Informatica |
Modern MDM requirements have evolved beyond batch match-merge operations. Real-time entity resolution APIs are now required for customer experience use cases where identity must be resolved at the point of interaction in milliseconds. ML-based probabilistic matching with active learning, where the system improves with each stewardship decision, is replacing static rule-based matching for most organizations.
Financial services MDM deserves separate consideration. GoldenSource, Gresham Alveo, and Gresham EDM are specialist platforms for financial instrument reference data, corporate actions, and entity hierarchies, serving requirements that general-purpose enterprise MDM platforms cannot address.
2.4.1.5 Document Management
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Microsoft SharePoint / Syntex | Microsoft | Cloud (Microsoft 365) | Document management, content types, automated classification via Syntex AI, compliance labels, Power Automate integration, SharePoint Premium AI features, Copilot over documents | No | Dominant enterprise document management; Syntex AI adds automated classification and metadata extraction; Microsoft 365 Copilot over documents is powerful; deep compliance integration | Primarily within Microsoft ecosystem; governance complexity at very large scale; SharePoint Premium pricing adds up; search quality across large tenants requires tuning |
| OpenText Content Suite / Documentum | OpenText | On-prem / Cloud | Enterprise content management, records management, archiving, document lifecycle workflows, compliance, OpenText Intelligent Capture for document ingestion | No | Long-established ECM; very strong in regulated industries (pharma, legal, financial); mature records management and compliance capabilities; broad deployment across large enterprises | Legacy architecture limiting agility; modernization to cloud is slower than Microsoft; complex licensing; less compelling for new deployments versus modern cloud-native alternatives |
| Box | Box | Cloud (SaaS) | Cloud content management, Box AI for classification and content extraction and Q&A over documents, metadata templates, Box Sign, secure collaboration, developer APIs | No | Strong enterprise cloud content platform; Box AI adds classification, extraction, and document Q&A natively; excellent API for integration; security and compliance certifications comprehensive | Collaboration focus rather than deep governance; metadata model less powerful than SharePoint for complex content types; ECM workflow depth less than OpenText |
| Data Dynamics Zubin | Data Dynamics | Cloud / On-prem | Unstructured data management platform, NAS/S3/SharePoint/file server content management, metadata extraction, retention automation, storage tiering, GDPR and HIPAA compliance for documents | No | Comprehensive unstructured data lifecycle management combining governance, compliance, cost optimization, and content search; strong for organizations with large NAS and file server estates | Primarily unstructured data focus; structured database governance is not the strength; less well known than SharePoint or OpenText in ECM market |
| Alfresco (Hyland) | Hyland | Cloud / On-prem | Open-source ECM, document workflows, records management, enterprise search, process automation, API-first integration | Yes (Community Edition) | Strong open-source ECM heritage; Hyland acquisition brings enterprise support; good process workflow automation; API-first design for data pipeline integration; flexible deployment | Community edition limited vs. enterprise; smaller market than SharePoint or OpenText; Hyland portfolio complexity post-acquisitions |
| M-Files | M-Files | Cloud / On-prem | Metadata-driven document management, AI-based automatic classification, version control, workflow automation, vault-based access control, Teams and Salesforce integration | No | Unique metadata-centric approach where documents are found by what they are rather than where they are stored; strong AI classification; good, regulated industry support | Smaller market presence; metadata model requires investment to design and maintain; less known outside Nordics and professional services markets |
| ABBYY Vantage | ABBYY | Cloud / On-prem | Intelligent document processing, OCR, form and table extraction, NLP-based field recognition, low-code skill builder, API-first integration, human-in-the-loop review | No | Market leader for automated document extraction and processing; IDP platform converts documents to structured data; high OCR accuracy on complex layouts; API-first for pipeline integration | Primarily document extraction rather than content storage and lifecycle management; integration effort required for ECM workflows; skilled builder needed for complex document types |
| Coveo | Coveo | Cloud (SaaS) | AI-powered enterprise search across SharePoint/Confluence/Salesforce/web/email, relevance tuning, behavioral analytics, semantic search, customer-facing search integration | No | Best unified search across heterogeneous document repositories; AI relevance model improves continuously with usage; good for customer-facing and employee-facing search use cases | Primarily a search layer, not a document lifecycle management platform; governance capabilities limited; pricing significant for large enterprises |
Document management has experienced a step-change transformation with the embedding of AI capabilities. The traditional distinction between ECM platforms focused on storage and lifecycle management and AI platforms focused on content extraction is dissolving: modern ECM vendors (Microsoft Syntex, Box AI, M-Files) now offer intelligent classification, automated metadata generation, and document Q&A.
For most enterprises, the document management stack has two layers: a storage and governance layer (SharePoint, Box, or OpenText for lifecycle management and compliance) and an AI processing layer (ABBYY, AWS Textract, or Azure Document Intelligence for converting document content into structured pipeline-ready data). Organizations should evaluate both layers and ensure they are connected, as the value of AI document extraction is fully realized only when the extracted structured data flows into governed analytical stores and AI training pipelines.
2.4.2 Data Catalog and Marketplace
The data catalog and marketplace layer covers three closely related capabilities: the central metadata repository for all data assets (catalog), the tracking of data movement and transformation (lineage), and the shared business vocabulary that aligns technical metadata with business meaning (business glossary). Together these form the foundation of the governed, discoverable data estate. Catalog marketplace features enable internal and external data product publication and consumption.
2.4.2.1 Data Catalog
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Collibra Data Intelligence Cloud | Collibra | Cloud / On-prem | Policy-driven catalog, automated classification, lineage, business glossary, data marketplace, document assets via DeasyLabs; DCAT metadata export supported | No | Most comprehensive enterprise catalog; gold standard governance workflows; strong unstructured coverage via DeasyLabs and BigID integrations | High implementation effort and cost; requires dedicated stewardship team; complex for smaller organizations |
| Alation Data Catalog | Alation | Cloud / On-prem | Behavioral ML auto-documentation, curation campaigns, stewardship dashboards, file system scanning, governance workflows; REST API for DCAT alignment | No | Strong behavioral analytics surface curation priorities; trusted enterprise catalog with proven ROI; extending toward unstructured asset types | DCAT export requires custom integration; unstructured coverage still maturing; implementation effort significant |
| Atlan | Atlan | Cloud (SaaS) | Modern developer-plus-analyst catalog, embedded lineage (300+ sources), policy management, AI metadata agents, custom asset types for documents and models; OpenMetadata standards | No | Fastest-growing modern catalog; API-first; excellent UX; custom asset types well-suited to non-tabular data; strong OpenMetadata standards alignment | Newer vendor; enterprise breadth building; governance workflow depth developing compared to Collibra |
| DataHub | Acryl Data / OSS | OSS / Cloud | Extensible metadata graph, configurable entities, push/pull ingestion, column-level lineage, custom entities for documents and ML models; DCAT mapping via custom ingestion | Yes (Apache 2.0) | Best OSS catalog; highly extensible architecture; custom entity model uniquely suited to non-tabular assets; strong community | Requires engineering resource for OSS operation; UI less polished than commercial tools; DCAT support requires custom work |
| OpenMetadata | OpenMetadata (OSS) | OSS / Cloud | Unified metadata platform, 80+ connectors, data quality integration, collaboration, schema versioning, REST APIs; DCAT-compatible metadata model | Yes (Apache 2.0) | Strong open-source alternative; active community adding connectors; DCAT-compatible design from the outset; good governance features | Smaller ecosystem than DataHub; production deployments require engineering investment; commercial support limited |
| Snowflake Horizon Catalog | Snowflake | Cloud (SaaS) | Native catalog for Snowflake objects, automated tagging, sensitivity classification, governance policies, access history, data quality rules, cross-cloud metadata; DCAT metadata exportable | No | Zero-friction for Snowflake users; unified catalog and governance in one platform; strong classification and policy enforcement natively | Snowflake-only scope; external source coverage limited without additional tooling; less suitable as enterprise-wide catalog |
| Databricks Unity Catalog | Databricks | Cloud (SaaS) | Unified catalog for tables, models, notebooks, and files in Delta Lake; column-level lineage, fine-grained access control, AI/BI governance; Delta Sharing for external catalog exchange | No | Excellent for Databricks-centric data estates; covers structured and ML assets in one place; strong lineage for Delta pipelines | Databricks-centric; multi-cloud catalog consolidation complex; limited business user tooling compared to Collibra or Atlan |
| Microsoft Purview | Microsoft | Cloud (Azure / M365) | Automated data map, sensitivity labels, DLP integration, Teams/M365 lineage, SharePoint and Exchange cataloging; DCAT-inspired taxonomy model | No | Best catalog for unstructured and semi-structured Microsoft content; unique M365 coverage; expanding structured DW coverage rapidly | Azure/M365 ecosystem dependency; DCAT compliance limited; governance workflows less mature than dedicated catalog vendors |
| Google Dataplex | Cloud (GCP) | Unified data management across BigQuery, GCS, and Bigtable; automated tagging, data quality, lineage, GCS object cataloging; BigQuery Data Catalog integration; DCAT-based APIs | No | Native GCP integration; GCS object coverage brings unstructured files into catalog; DCAT-based API design; strong BigQuery lineage | GCP-centric; limited outside Google Cloud; governance depth less than specialist catalog tools | |
| Informatica Enterprise Data Catalog | Informatica | Cloud / On-prem | AI-powered catalog (CLAIRE), automated scanning of 300+ sources including file systems and cloud storage, S3 and NAS coverage; DCAT metadata export available | No | Deep Informatica suite integration; CLAIRE AI provides impressive, automated enrichment; broad source coverage including file systems | Best value inside Informatica ecosystem; standalone adoption less compelling; complex deployment |
| IBM Knowledge Catalog | IBM | Cloud (IBM Cloud) | Automated metadata enrichment, data classes, business terms, Watson AI governance, Cloud Pak for Data integration; DCAT-aligned metadata model | No | Strong Watson AI enrichment; good compliance mapping; IBM Cloud-native deployment; DCAT alignment in metadata model | IBM Cloud-centric; limited adoption outside IBM ecosystem; complex setup; pricing opacity |
| Data Dynamics Zubin | Data Dynamics | Cloud / On-prem | Unstructured data catalog and governance across NAS, S3, SharePoint, file servers; content classification, metadata extraction, GDPR inventory, retention management | No | Strong unstructured data catalog; storage cost and compliance optimization alongside cataloging; good for file-heavy organizations | Primarily unstructured focus; structured database catalog capability limited; less known than BigID |
| BigID | BigID | Cloud (SaaS) | Cataloging across 500+ structured and unstructured source types, PII inventory, sensitivity classification, S3/SharePoint/NAS/email cataloging, data risk scoring | No | Widest source coverage for unstructured cataloging; identifies sensitive data anywhere in the estate; proven at enterprise scale | Primarily security and privacy-focused rather than analytics catalog; lineage and business glossary less mature |
| erwin Data Intelligence | erwin (Quest) | On-prem / Cloud | Metadata management, lineage, business glossary, data literacy, process modelling, DCAT export support for open data publishing | No | Strong in regulated industries; deep data modelling heritage; DCAT export for open data use cases; good compliance documentation | Modernizing slowly to cloud; less competitive UX compared to modern catalogs; smaller community |
| Securiti.ai Data Catalog | Securiti | Cloud (SaaS) | Automated data discovery and classification across structured and unstructured sources, AI-powered PII and sensitive data cataloging, privacy context layered on catalog assets, cross-cloud scanning (AWS, Azure, GCP), data inventory for GDPR and CCPA compliance, catalog integrated with consent and DSAR workflows | No | Unique in combining catalog with privacy intelligence natively; auto-classification of sensitive data across 500+ source types means catalog entries arrive with privacy context already attached; strong for organizations where compliance is the primary driver for cataloging; cross-cloud coverage is broad | Catalog depth is secondary to the privacy and compliance mission; business glossary, stewardship workflows, and data lineage are less developed than Collibra or Atlan; not the right primary catalog for organizations whose main need is analytics governance rather than privacy compliance; best treated as a specialist privacy catalog rather than a general-purpose enterprise catalog |
| Ataccama ONE Catalog | Ataccama | On-prem / Cloud | Automated data discovery and profiling, AI-powered metadata classification, business glossary, data quality scoring surfaced in catalog, MDM integration, data lineage, role-based access, European data residency options | No | Strong combination of catalog and data quality in a single platform; DQ scores are natively embedded in catalog asset views so consumers can see fitness-for-purpose before using data; MDM integration means mastered entities are cataloged with quality context; good option for regulated industries requiring EU data residency | Less well known than Collibra or Alation in the catalog market; primarily gains traction where DQ and MDM are also in scope rather than as a standalone catalog purchase; UI and developer experience less modern than Atlan; smaller partner ecosystem and community than the market leaders |
Enterprise data catalogs are evaluated on five dimensions: automated metadata harvesting with minimal manual curation overhead; column-level lineage across heterogeneous systems; AI-powered enrichment and search; collaborative governance workflows; and openness through APIs and standards such as DCAT. A sixth dimension is becoming critical: unstructured asset coverage. Organizations that govern only structured data are leaving the majority of their data estate ungoverned.
Most enterprises will combine two or three catalog tools: a comprehensive governance platform, a modern developer-first catalog, and a specialist unstructured data catalog.
2.4.2.2 Data Lineage
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS / OpenLineage | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Collibra Lineage (incl. IBM Manta) | Collibra | Cloud / On-prem | Automated lineage across 60+ systems, column-level, data flow visualization, impact analysis, regulatory reports; deep SQL parsing via IBM Manta licensing | No / OpenLineage connector | Most comprehensive enterprise lineage; IBM Manta licensing added industry-leading SQL parsing; document flow tracking via Manta parser | High cost and implementation complexity; Manta integration still maturing post-licensing; resource-intensive scanning |
| IBM Manta | IBM (acquired Manta) | On-prem / Cloud | Deep SQL parsing for 30+ platforms, stored procedures, ETL tool analysis, cross-system lineage, BI report lineage, document flow modelling | No / OpenLineage output | Most accurate SQL-parsing lineage in market; acquired by IBM then licensed to Collibra; strong BI layer coverage; document pipeline lineage capability | Post-acquisition positioning unclear; requires Collibra or IBM platform; complex to deploy standalone |
| Alation Lineage | Alation | Cloud / On-prem | Query-based lineage mining, behavioral intelligence, column-level, impact analysis, integrated catalog; OpenLineage event ingestion | No / OpenLineage supported | Accurate lineage through query mining rather than parsing; well-integrated with Alation catalog; OpenLineage events supported for pipeline lineage | Limited lineage outside SQL workloads; stored procedure and ETL parsing less deep than IBM Manta |
| Atlan Lineage | Atlan | Cloud (SaaS) | Automated lineage from 300+ sources, column-level, OpenLineage native, impact analysis, data product lineage, custom entity lineage | No / OpenLineage native | Modern approach with OpenLineage native integration; excellent visualization; growing asset type coverage including non-tabular; fast connector growth | Newer vendor; lineage depth for complex SQL stored procedures still maturing compared to IBM Manta or Informatica |
| DataHub Lineage | Acryl / OSS | OSS / Cloud | Push/pull lineage, column-level, OpenLineage integration, transformation node details, custom entity lineage for documents and models | Yes / OpenLineage native | Best OSS lineage; extensible custom entities allow lineage for document and model pipelines; OpenLineage native; active community | Requires engineering resource for production operation; UI less polished than commercial tools; RBAC governance less mature |
| Microsoft Purview Lineage | Microsoft | Cloud (Azure) | Automated lineage from ADF, Synapse, Power BI, Databricks; custom OpenLineage events ingestion; M365 content movement tracking; SharePoint lineage | No / OpenLineage supported | Strong within Microsoft stack; M365 content lineage is uniquely capable; growing cross-stack coverage via OpenLineage integration | Azure/M365-centric; lineage depth for non-Microsoft systems requires custom work; limited cross-cloud lineage |
| Informatica IDMC Lineage | Informatica | Cloud / On-prem | End-to-end lineage across 500+ sources, CLAIRE AI enrichment, business process lineage, file system lineage; OpenLineage import | No / OpenLineage import | Comprehensive enterprise lineage across the broadest source set; deep native Informatica pipeline coverage; CLAIRE AI enrichment of lineage nodes | Best value inside Informatica ecosystem; standalone investment significant; complex deployment |
| dbt Lineage | dbt Labs | OSS / Cloud | DAG-based lineage within dbt models, column-level lineage (dbt 1.6+), metadata API for downstream catalog consumption; OpenLineage events via dbt-ol plugin | Yes / OpenLineage via plugin | Native lineage for dbt ELT transforms; best-in-class DAG visualisation; column-level lineage growing; OpenLineage plugin available | Coverage limited to dbt models; no lineage for data outside dbt; catalog coverage requires integration with Atlan/DataHub/Alation |
| OpenLineage | Linux Foundation (OSS) | OSS Standard | Open specification for lineage events, integrations with Airflow, Spark, dbt, Flink, Trino; Marquez reference backend; enables cross-platform lineage graphs | Yes / Is the standard | Foundational open standard; prevents vendor lock-in for lineage data; growing adoption across all major pipeline tools; not a UI product but the connective tissue | Standard only, not a product; requires a compatible backend (Marquez or commercial catalog); UI and search require additional tooling |
| Solidatus | Solidatus | Cloud / On-prem | Visual data flow modelling, regulatory lineage (BCBS239, DORA, MiFID II), cross-enterprise mapping, document flow and process lineage modelling | No / Limited OpenLineage | Strong in financial services regulatory compliance lineage; model-driven approach handles complex multi-system estates well | Manual modelling is time-consuming at scale; automated discovery less sophisticated than Collibra/Informatica; niche financial services focus |
| Octopai | Octopai / Cloudera | SaaS / On-prem | Automated BI lineage for SSRS, Tableau, Power BI, Cognos, impact analysis, cross-BI platform coverage; OpenLineage alignment in progress | No / Partial OpenLineage | Specialist in BI-layer lineage; acquired by Cloudera; strong in regulated industries needing report-to-source lineage trails | Post-acquisition roadmap evolving; BI specialisation limits general pipeline lineage; less suitable as primary enterprise lineage tool |
Column-level lineage has become the minimum acceptable standard; table-level lineage is no longer sufficient for impact analysis, GDPR data subject requests, or AI training data provenance. The OpenLineage specification is driving standardisation across Airflow, Spark, dbt, and Flink, enabling lineage events to flow into centralised stores without vendor lock-in. IBM Manta (acquired by IBM, licensed to Collibra) remains the most accurate SQL parsing lineage tool, particularly valuable for organizations with large stored procedure estates and complex ETL transformations.
2.4.2.3 Business Glossary
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Collibra Business Glossary | Collibra | Cloud / On-prem | Hierarchical term management, policy links, asset associations, stewardship workflows, term lifecycle management, GDPR and regulatory term mapping | No | Most comprehensive business glossary with full governance workflow; term lifecycle management mature; links directly to lineage, catalog, and policy engine | High implementation effort; requires dedicated stewardship program; premium pricing; governance workflow complexity can slow term creation |
| Atlan Business Glossary | Atlan | Cloud (SaaS) | AI-assisted term creation, term-to-asset linking, embedded glossary in catalog UI, Slack/Teams term lookup, bulk glossary import/export | No | Modern developer-friendly glossary embedded in catalog; AI assistance reduces manual effort; excellent UX for daily stewardship; fast-growing adoption | Governance workflow depth building; stewardship maturity less than Collibra; newer product with building enterprise track record |
| DataHub Glossary | Acryl / OSS | OSS / Cloud | Term hierarchy, term-to-entity linking, custom term metadata, bulk glossary upload, access-controlled stewardship | Yes (Apache 2.0) | Best OSS business glossary; flexible extensible model; term entities can be linked to any custom entity type; active community; free for self-managed deployments | Requires engineering resource for production operation; stewardship workflow less mature than commercial tools; UI requires polish |
| Informatica Business Glossary | Informatica | Cloud / On-prem | Term management, policy association, integration with IDMC data catalog, DQ rule links, CLAIRE AI term suggestions | No | Integrated business glossary within comprehensive Informatica platform; CLAIRE AI assists term creation; deep links to DQ rules and governance policies | Best value inside Informatica ecosystem; standalone adoption less compelling; UI less modern than Atlan or Collibra Cloud |
| Alation Glossary | Alation | Cloud / On-prem | Business terms with trust flags, curation campaigns, term-to-query and asset linking, stewardship assignment, governance integration | No | Governance through usability; trust flags and usage data drive stewardship naturally; well-integrated with Alation catalog and governance workflows | Primarily structured data assets; governance workflow depth less than Collibra; UI for glossary management less rich than specialist tools |
| Microsoft Purview Glossary | Microsoft | Cloud (Azure) | Business terms, term templates, expert and steward assignments, term-to-asset linking, classification-driven term application across M365 and Azure assets | No | Integrated across Microsoft data estate; term-to-asset links extend to SharePoint, Exchange, and Teams content alongside databases; good compliance use cases | Azure/M365-centric; governance workflow less mature than Collibra; term management UI functional but basic compared to specialist tools |
| erwin Business Glossary | erwin (Quest) | On-prem / Cloud | Business term management, data modelling integration, regulatory compliance mapping, data literacy module, glossary publishing | No | Strong data modelling integration; long heritage in enterprise glossary management; good for organizations where data model is the source of truth for business definitions | Modernising slowly to cloud; less competitive UX compared to modern catalogs; smaller community and adoption outside traditional data modelling focus |
| Ataccama ONE Business Glossary | Ataccama | Cloud / On-prem | Hierarchical business term management; term relationships and synonyms; stewardship workflows with approval chains; AI-assisted term suggestions from data asset scanning; linkage to data catalog assets, data quality rules, and classification policies; policy propagation from glossary terms; versioning and change history; embedded reference data management | No | Tightly integrated with the broader Ataccama ONE platform — glossary terms link directly to catalog assets, lineage, data quality rules, and access policies without manual mapping; AI-assisted term harvesting reduces manual entry burden; strong stewardship workflow with configurable approval chains; reference data management is bundled, which many standalone glossary tools lack; mature enterprise deployments across financial services and healthcare where controlled vocabulary is a regulatory requirement | Full value requires adoption of the broader Ataccama ONE platform — the glossary in isolation is less compelling than dedicated standalone tools; UI is functional but less modern than newer entrants such as Atlan; implementation and configuration complexity is higher than cloud-native alternatives; pricing is not publicly listed and typically requires a full platform commitment rather than a glossary-only purchase; smaller partner ecosystem compared to Collibra or Informatica |
The business glossary has evolved from a passive documentation repository into an active governance instrument. Business terms link to physical assets, drive classification policies, trigger data quality rules, and enforce access controls. Modern glossaries integrate AI-assisted term suggestion, automated linking from metadata scanning, and stewardship dashboards that show term coverage and staleness. The most important design principle is active stewardship: a glossary that is not continuously maintained becomes a liability as it drifts from business reality. Automated term suggestion from LLMs scanning data asset descriptions can significantly reduce the manual burden of glossary maintenance.
2.4.2.4 Data and AI Marketplace
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Snowflake Marketplace | Snowflake | Cloud (SaaS) | Third-party and first-party data/app listings; secure data sharing without data movement; usage-based pricing; native app framework | No | Tightly integrated with Snowflake compute; large catalogue of commercial data providers; zero-copy sharing | Limited to Snowflake ecosystem; provider onboarding complexity |
| AWS Data Exchange | Amazon Web Services | Cloud (SaaS) | Licensed third-party data delivery to S3 and Redshift; subscription management; data grants; API and file delivery | No | Broad catalogue of financial, geospatial, and media datasets; seamless AWS integration; billing through AWS | AWS-centric; limited support for non-AWS consumers; governance tools are basic |
| Google Analytics Hub | Google Cloud | Cloud (SaaS) | Cross-organization data sharing via BigQuery linked datasets; listing management; subscriber controls; audit logging | No | Native BigQuery integration; granular subscriber access controls; supports both internal and commercial sharing | Tied to BigQuery; smaller provider ecosystem than AWS Data Exchange |
| Databricks Marketplace | Databricks | Cloud (SaaS) | Open data, models, and notebooks listings; Delta Sharing protocol for cross-platform delivery; provider and consumer portals | Partial (Delta Sharing) | Supports data, ML models, and solution accelerators; open Delta Sharing standard works outside Databricks | Younger ecosystem with fewer commercial data providers; governance tooling still maturing |
| Collibra Data Marketplace | Collibra | Cloud / On-prem | Self-service data product discovery; shopping-cart access requests; linked to Collibra catalog and governance; usage analytics | No | Deep governance integration; policy-driven access requests; data product lifecycle management | High licensing cost; dependent on broader Collibra platform adoption |
| Atlan Data Products | Atlan | Cloud (SaaS) | Data product publishing and discovery; linked lineage and quality scores; consumer access requests; Slack and Jira integrations | No | Modern UX; strong metadata and lineage context on each product; collaborative workflows | Relatively new; AI marketplace capabilities limited; mid-market focus |
| Hugging Face Hub | Hugging Face | Cloud / Self-hosted | Model and dataset repository; model cards; versioning; API inference; private and gated repos; Spaces for demos | Yes | Largest open-source model and dataset ecosystem; community contributions; broad framework support | Governance and enterprise access controls are basic; self-hosting requires significant infrastructure |
| NVIDIA NGC | NVIDIA | Cloud / On-prem | GPU-optimised container registry; pre-trained models; Helm charts; software SDK catalogue; enterprise support tier | Partial | Optimised for NVIDIA GPU hardware; curated AI models and frameworks; validated containers | Vendor-locked to NVIDIA hardware; limited data marketplace capabilities; primarily infrastructure-focused |
| Azure AI Model Catalog | Microsoft | Cloud (SaaS / Azure) | Curated foundation model listings from OpenAI, Meta, Mistral, and others; fine-tuning; deployment to Azure ML endpoints; benchmarks | Partial | Broad model variety from multiple providers; integrated with Azure ML and security controls; enterprise SLA | Azure-only deployment; model selection and pricing can be complex; governance tooling less mature than data-side |
The marketplace category sits at the intersection of data management and commercial operations. Cloud platform vendors have moved aggressively to embed marketplaces within their data ecosystems: Snowflake, AWS, Google, and Databricks each offer marketplace capabilities that allow providers to publish and consumers to subscribe with billing handled through the platform. This tight integration lowers friction for data consumers but creates ecosystemic lock-in for providers who must distribute separately across platforms to reach a broad audience.
Internal data marketplaces, represented by tools such as Collibra Data Marketplace and Atlan Data Products, address the challenge of data democratisation within an enterprise. The design principle is to treat internal datasets as products with documented interfaces, SLAs, and ownership, rather than as raw assets accessed by whoever can find the connection string.
AI marketplaces have emerged as a distinct and rapidly growing segment. Hugging Face Hub has become the de facto open-source distribution platform for models and datasets. Governance remains the primary challenge across the marketplace category. External data products carry licensing, lineage, and freshness obligations that must be tracked through to analytical use. Organizations building on external models need to treat marketplace subscriptions with the same rigour applied to software dependencies, including version pinning, vulnerability monitoring, and documented approval for production use.
2.4.3 Data Store
The data store layer covers all purpose-built storage systems across the full range of data types and access patterns. The modern enterprise data platform requires multiple store types: object storage for raw files and lakehouse tables, relational databases for transactional workloads, document and key-value stores for flexible schemas, vector databases for AI semantic search, graph databases for relationship-centric analytics, data warehouses for SQL analytics, and data lakehouses combining open formats with SQL query capabilities.
2.4.3.1 Object Store
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Amazon S3 | AWS | Cloud (AWS) | Massively scalable object storage, S3 Select for partial object read, Intelligent-Tiering for cost optimization, S3 Object Lambda, Macie for sensitive data discovery, event notifications | No | Most widely adopted object store; broadest ecosystem of tools and integrations; Intelligent-Tiering reduces cost automatically; S3 Select improves query performance; Macie adds security scanning | AWS-centric; egress costs can be significant; permission model (bucket policies, IAM, ACLs) is complex at scale; S3 is not a queryable database, requires query layer |
| Azure Blob Storage / ADLS Gen2 | Microsoft | Cloud (Azure) | Blob Storage plus ADLS Gen2 (hierarchical namespace for Hadoop compatibility), access tiers (Hot/Cool/Archive), lifecycle management, Azure Purview integration, Data Lake Storage | No | ADLS Gen2 hierarchical namespace enables POSIX-compatible file system access; deep integration with Azure analytics ecosystem; Purview governance of blob and ADLS content; strong enterprise compliance | Azure-centric; cross-cloud data access adds latency and cost; hierarchical namespace requires migration from flat blob structure; Purview scanning adds operational overhead |
| Google Cloud Storage (GCS) | Cloud (GCP) | Multi-region and multi-class storage, strong consistency, GCS Object Lifecycle, BigQuery external tables over GCS, Google-managed encryption, Dataplex scanning | No | Strong consistency model simplifies application design; native BigQuery and Dataflow integration; Dataplex discovery and governance of GCS objects; good multi-region replication options | GCP-centric; egress costs from GCP can be significant; governance tooling less mature than AWS+Macie or Azure+Purview for non-GCP workflows | |
| MinIO | MinIO | OSS / Cloud (MinIO Operator) | S3-compatible object storage for on-premises and Kubernetes, high performance (100+ GB/s), erasure coding, encryption, multi-cloud gateway capability | Yes (GNU AGPL) | Best open-source S3-compatible object store; widely used for on-premises lakehouse deployments; Kubernetes-native operator; high throughput suitable for ML training data and analytics workloads | AGPL license considerations for embedded commercial use; operator complexity for large Kubernetes deployments; enterprise features require commercial license |
| Ceph Object Storage (RADOS) | Red Hat / Ceph (OSS) | OSS / On-prem | Distributed object, block, and file storage, S3-compatible REST API, erasure coding, scale-out architecture, Rook-Ceph for Kubernetes | Yes (LGPL) | Fully open-source distributed storage; S3 and Swift compatibility; strong in OpenStack and bare-metal data center deployments; active community | Operational complexity; requires dedicated Ceph expertise; performance tuning non-trivial; less suitable for cloud-native deployments versus MinIO |
| Cloudflare R2 | Cloudflare | Cloud (SaaS) | S3-compatible object storage with zero egress fees, multi-region, Workers integration for serverless processing at the edge, strong API compatibility | No | Zero egress fees are a major cost advantage for multi-cloud and data distribution use cases; S3 API compatibility; strong for content delivery and AI model artefact storage | Newer product with building enterprise references; limited native analytics integrations compared to AWS S3 or GCS; no native ML or data lake specific features |
| Backblaze B2 | Backblaze | Cloud (SaaS) | S3-compatible low-cost object storage, strong Cloudflare partnership for free egress, simple pricing model, lifecycle rules | No | Most cost-effective cloud object storage for archival and backup; free egress via Cloudflare partnership; simple transparent pricing; good for unstructured data cold storage | Not suitable for primary data lake analytics; limited advanced features; lower performance ceiling than AWS S3 or Azure ADLS; less ecosystem integration for data engineering tools |
Object storage has become the universal foundation layer for enterprise data platforms. The dominant pattern is landing all raw data, structured and unstructured, into an object store in open formats before applying compute engines for processing. AWS S3 remains the market standard for cloud-native deployments, with its breadth of integrations giving it a significant practical advantage. Azure ADLS Gen2 is the strategic choice for Microsoft-committed organizations. MinIO enables on-premises lakehouses with full S3 API compatibility. The critical governance consideration is that object stores contain both structured analytical data (Iceberg and Delta tables) and unstructured files (documents, model artefacts, images), requiring the catalog and governance layer to cover both types consistently.
2.4.3.2 Relational and OLTP Databases
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| PostgreSQL | PostgreSQL (OSS) | OSS / Managed cloud | ACID transactions, advanced SQL, JSONB, rich extensions (PostGIS, pgvector, TimescaleDB, Citus), logical replication, FDW | Yes (PostgreSQL licence) | Gold standard open-source RDBMS; most-loved database (Stack Overflow surveys); managed on all major clouds; pgvector adds vector search natively | Vertical scaling constraints without Citus; complex HA setup requires additional tooling; operational expertise needed for large deployments |
| MySQL / MariaDB | Oracle / MariaDB Foundation | OSS / Managed cloud | Widely deployed RDBMS, InnoDB ACID, replication, MySQL HeatWave for in-database analytics and ML | Yes (GPL) | Most deployed RDBMS globally; HeatWave adds in-database ML at low cost; MariaDB is the fully open fork; ubiquitous managed service availability | HeatWave is Oracle/MySQL specific; MariaDB and MySQL diverging; limited advanced analytics compared to Postgres extensions |
| Oracle Database | Oracle | On-prem / OCI / Exadata | Enterprise RDBMS, RAC HA, Autonomous DB, JSON Duality views, in-database ML, Exadata hardware optimisation, Multitenant | No | Dominant in large enterprises and financial services; very powerful feature set; Autonomous DB reduces DBA overhead | Very high licensing and support cost; vendor lock-in is significant; cloud-native competition has eroded competitive moat for new builds |
| Microsoft SQL Server / Azure SQL | Microsoft | On-prem / Azure | Enterprise RDBMS, Always On HA, In-Memory OLTP, Synapse Link, Fabric SQL database, AI integration via Copilot | No | Deeply embedded in enterprise application estates; Azure SQL adds fully managed cloud; Fabric SQL aligns with analytics platform | Licensing complexity; Windows heritage creates some Linux friction; Azure-centric cloud story |
| Amazon Aurora | AWS | Cloud (AWS) | MySQL/PostgreSQL-compatible managed DB, auto-scaling storage, Aurora Serverless v2, Aurora Limitless for horizontal scaling | No | Dominant managed RDBMS on AWS; excellent performance relative to cost; Serverless v2 widely adopted for variable workloads | AWS-only; Aurora Limitless still maturing for very large-scale workloads; PostgreSQL compatibility is close but not identical |
| CockroachDB | Cockroach Labs | Cloud (SaaS) / OSS | Distributed ACID SQL, multi-region active-active, PostgreSQL-compatible wire protocol, geo-partitioning, serverless tier | Partial (BSL licence) | Modern geo-distributed RDBMS; strong consistency across regions; good for global applications requiring zero-downtime deployment | Higher latency than single-node Postgres for local workloads; BSL licence limits OSS use cases; operational complexity at scale |
| Google Spanner | Cloud (GCP) | Globally distributed ACID SQL, TrueTime clock, unlimited horizontal scale, strong global consistency, PostgreSQL-dialect support | No | Unique globally consistent distributed RDBMS; unlimited horizontal scale for writes; PostgreSQL dialect reduces migration friction | GCP-only; highest cost per unit of any RDBMS; over-engineered for workloads that do not require global distribution |
2.4.3.3 Document, Key-Value, and Wide-Column Stores
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| MongoDB / Atlas | MongoDB | OSS / Cloud (Atlas) | Document model, flexible schema, aggregation pipeline, Atlas Search, Atlas Vector Search, multi-cloud Atlas, time-series collections | Partial (SSPL) | Most popular NoSQL database; Atlas cloud is comprehensive; developer-friendly; Atlas Vector Search adds AI capability natively; strong mobile/edge via Realm | SSPL license limits some OSS use cases; Atlas can be expensive at scale; schema flexibility can be a governance liability without standards |
| Apache Cassandra / DataStax Astra | Apache / DataStax | OSS / Cloud | Wide-column, linear write scalability, multi-datacenter replication, CQL, time-series friendly write patterns, Cassandra Query Language | Yes (Apache 2.0) | Battle-tested for high write throughput at extreme scale; DataStax Astra adds managed cloud; strong for IoT and time-series write workloads | Eventually consistent by default; complex data modelling required; limited query flexibility compared to relational; operational expertise needed |
| Redis / Redis Stack | Redis Inc. / OSS | OSS / Cloud | In-memory key-value plus rich data structures, Pub/Sub, Redis Streams, vector search (RedisVSS), JSON module, search module | Partial (RSAL/SSPL) | Universal caching layer; sub-millisecond latency; Redis Stack adds search, graph, time-series in one product; widely adopted for session and real-time data | Memory-cost constraints limit data volume; persistence is secondary; license changed from BSD created some ecosystem fragmentation (Valkey fork) |
| Amazon DynamoDB | AWS | Cloud (AWS) | Serverless key-value and document, single-digit ms latency at scale, DynamoDB Streams, global tables, PartiQL | No | Dominant serverless NoSQL on AWS; extreme operational simplicity; very high throughput ceiling; global tables for multi-region active-active | AWS-only; cost model is unpredictable without careful capacity planning; limited query flexibility; data modelling requires DynamoDB-specific patterns |
| Elasticsearch / OpenSearch | Elastic / AWS | Cloud / OSS | Full-text search over unstructured and semi-structured data, vector search (kNN), log analytics, APM, SIEM, aggregations | Yes (OpenSearch Apache 2.0) | De facto standard for log analytics; critical for unstructured data search; OpenSearch is the fully open fork; kNN vector search added for AI use cases | Not a primary operational database; query consistency model limits transactional use; operational complexity for large clusters; cost can scale quickly |
| Couchbase Capella | Couchbase | Cloud / On-prem | Document model, N1QL SQL++, memory-first architecture, mobile sync (Couchbase Lite), vector search, full-text search | No | Strong for latency-sensitive edge and mobile use cases; Capella adds managed cloud; SQL++ is powerful; memory-first delivers consistent sub-ms reads | Smaller market than MongoDB; mobile sync adds complexity; community and ecosystem smaller than Cassandra or Redis |
2.4.3.4 Vector Databases (AI and RAG Infrastructure)
| Tool / Platform | Vendor | Deployment | Vector Features | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Pinecone | Pinecone | Cloud (SaaS) | Managed vector search, ANN indexing (HNSW/IVF), metadata filtering, hybrid sparse-dense search, real-time upserts, serverless tier | No | Market-leading managed vector database; zero operational overhead; strong performance at scale; excellent documentation and SDK support; serverless tier reduces cost for variable workloads | Fully managed only, no self-hosted option; cost can escalate at high query volume; Pinecone-specific API creates some lock-in risk |
| Weaviate | Weaviate | OSS / Cloud (SaaS) | Open-source vector DB, object and vector storage, GraphQL and REST APIs, module ecosystem (text2vec, img2vec), hybrid search, multi-tenancy | Yes (BSD 3-Clause) | Strong OSS community; broad embedding model integration; GraphQL API is flexible; multi-tenancy for SaaS applications; well-maintained and production-ready | Self-hosted operational complexity at scale; GraphQL learning curve; performance tuning requires expertise; cloud offering less mature than Pinecone |
| Qdrant | Qdrant | OSS / Cloud (SaaS) | Open-source vector search, HNSW ANN, rich metadata filtering, Rust-based for performance, payload indexing, sparse and dense vector support | Yes (Apache 2.0) | Excellent performance/resource ratio; Rust implementation provides memory efficiency; strong filtering capabilities; active development; cloud managed tier available | Younger project than Weaviate; smaller ecosystem of integrations; cloud service building enterprise references |
| Chroma | Chroma | OSS / Cloud | Lightweight open-source embedding store, Python and JavaScript SDKs, local and persistent modes, LangChain/LlamaIndex native integration | Yes (Apache 2.0) | Easiest to start with for RAG prototyping; native LangChain and LlamaIndex integration; excellent developer experience; great for development and small-scale production | Not designed for large-scale production deployments; limited distributed architecture; primarily a developer/prototyping tool rather than enterprise-grade infrastructure |
| Milvus / Zilliz | LF AI and Data / Zilliz | OSS / Cloud (Zilliz) | Open-source distributed vector DB, multiple ANN index types, GPU acceleration, hybrid search, multi-tenancy, Attu management UI | Yes (Apache 2.0) | Most production-ready OSS vector database for large scale; GPU acceleration for high-throughput indexing; Zilliz adds managed cloud and enterprise support | More complex to deploy and operate than Pinecone; resource-intensive; Zilliz cloud adds cost over self-managed; distributed setup requires operational maturity |
| pgvector (PostgreSQL) | PostgreSQL / OSS | OSS / Managed cloud | Vector search extension for PostgreSQL, HNSW and IVF indexes, exact and approximate nearest neighbor, native SQL integration | Yes (PostgreSQL license) | Zero additional infrastructure if Postgres already deployed; standard SQL for hybrid vector/relational queries; managed on AWS (RDS/Aurora), Azure, GCP | Performance lags purpose-built vector databases at very large scale; limited to Postgres deployment model; HNSW performance tuning requires expertise |
| Redis Vector Search | Redis Inc. | Cloud / On-prem | Vector search within Redis Stack, HNSW and FLAT indexes, hybrid keyword plus vector search, sub-ms query latency for cached vectors | Partial (RSAL) | Excellent for real-time vector search on frequently accessed data; cache-aligned architecture; low operational overhead if Redis already deployed | Memory-limited for very large vector datasets; best for hot vector sets rather than full corpus search; license change created some uncertainty |
| MongoDB Atlas Vector Search | MongoDB | Cloud (Atlas) | Vector search integrated in Atlas, ANN indexing via Atlas Search, hybrid text plus vector queries, native document plus vector storage | No (Atlas only) | Combines document storage and vector search in one database; no separate vector infrastructure needed; strong if Atlas already adopted for operational data | Requires Atlas (cloud-only); performance at very high vector scale less proven than Pinecone or Milvus; vector search features newer and still maturing |
| Snowflake Cortex Search | Snowflake | Cloud (SaaS) | Managed vector search within Snowflake, embedding generation via Cortex AI, hybrid search, integration with Snowflake tables and governance | No | Zero-friction for Snowflake users; vectors governed alongside tables in Horizon Catalog; embedding generation and search in one platform; strong for RAG over governed data | Snowflake-only; less flexible than dedicated vector databases; primarily suited to analytics and governed data RAG use cases rather than low-latency operational AI |
2.4.3.5 Graph Databases
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Neo4j | Neo4j | Cloud / On-prem | Property graph, Cypher query language, Graph Data Science library, vector plus graph hybrid queries, knowledge graph APIs | Partial (Community Edition) | Market leader in graph; strong in fraud detection, knowledge graphs, recommendation engines; Graph Data Science library is powerful for ML on graphs | Enterprise edition licensing cost; Cypher is proprietary (though OPENCYPHER open standard exists); performance degrades for very deep traversals |
| TigerGraph | TigerGraph | Cloud / On-prem | Distributed graph, GSQL native parallel query language, real-time deep link analytics, Graph Studio, ML Workbench, very high throughput graph queries | No | Purpose-built for deep link analytics at very large scale; GSQL enables complex multi-hop queries efficiently; strong for financial crime and supply chain use cases | GSQL has steep learning curve; smaller community than Neo4j; less mature developer tooling ecosystem; primarily enterprise-only pricing |
| Stardog | Stardog Union | Cloud / On-prem | Enterprise knowledge graph, RDF triple store, SPARQL, OWL reasoning, virtual graphs without data movement, Stardog Studio | No | Best enterprise knowledge graph combining RDF and property graph; virtual graph capability avoids data duplication; strong reasoning engine for complex ontologies | RDF/SPARQL expertise required; niche skills market; not suitable as a general-purpose operational database; primarily knowledge and ontology use cases |
| Ontotext GraphDB | Ontotext | Cloud / On-prem | RDF triple store, SPARQL 1.1, OWL2 reasoning, linked data platform, natural language to SPARQL, connectors for Elasticsearch and Solr | Partial (Free tier) | Strong semantic reasoning capabilities; good for life sciences, media, and financial linked data use cases; SPARQL federation for cross-graph queries | Niche RDF/semantic web skill requirement; smaller community than Neo4j; limited general-purpose adoption outside semantic data domains |
| Amazon Neptune | AWS | Cloud (AWS) | Managed property graph (Gremlin/openCypher) and RDF (SPARQL), serverless Neptune, ML on graphs (Neptune ML) | No | Good managed graph option for AWS; serverless tier reduces ops; Neptune ML adds graph-native machine learning; supports both property and RDF models | AWS-only; performance limits versus Neo4j and TigerGraph at very large scale graph traversals; serverless cold-start latency |
| InfluxDB / TimescaleDB | InfluxData / Timescale | Cloud / OSS | Time-series optimized storage, time-based aggregation and compression, InfluxQL/Flux/SQL, continuous queries, retention policies | Partial (OSS editions) | InfluxDB leads in IoT and metrics; TimescaleDB extends PostgreSQL for time-series with full SQL; continuous aggregation reduces query time at scale | InfluxDB Flux language is powerful but complex; TimescaleDB tied to PostgreSQL scaling; downsampling and retention policy management requires planning |
| SingleStore | SingleStore | Cloud / On-prem | Unified OLTP and OLAP (HTAP), in-memory first with disk persistence, real-time analytics, vector search, MySQL-compatible SQL | No | Unique HTAP architecture eliminates need for separate OLAP copy; sub-second analytics on live transactional data; vector search for AI applications built in | Complex pricing model; smaller market presence than Postgres or MySQL; operational expertise required for optimal performance tuning |
2.4.3.6 Data Warehouses
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Snowflake | Snowflake | Cloud (multi-cloud) | Columnar DWH, multi-cluster virtual warehouses, Data Sharing, Snowpark Python/Java/Scala, Cortex AI, Iceberg Tables, Dynamic Tables, Document AI | No | Market leader; pioneered compute/storage separation; strongest multi-cloud story; Cortex AI deeply integrated; Iceberg and Dynamic Tables expand to lakehouse architecture; platform expanding toward full data and AI services | Cost management requires discipline; Snowpark has performance considerations versus native Spark; pricing model complexity for diverse workload types |
| Google BigQuery | Cloud (GCP) | Serverless columnar DWH, BigQuery ML, BI Engine, Omni cross-cloud queries, Dataform, BigLake for open formats, Analytics Hub, Gemini integration | No | Strongest serverless model eliminates cluster management; BQML integrates ML within SQL workflow; Gemini deeply embedded from 2024; BigLake bridges DWH and lakehouse | GCP-centric; cross-cloud capabilities less mature than Snowflake; storage and compute costs need careful management; limited ecosystem outside Google stack | |
| Amazon Redshift | AWS | Cloud (AWS) | Columnar DWH, RA3 separate storage, Serverless Redshift, Spectrum for S3 queries, Data Sharing, Amazon Q AI integration, Streaming Ingestion | No | Long-established AWS DWH with deepest AWS ecosystem integration; Serverless reduces operational overhead; Amazon Q AI assistant adds natural language analytics | Performance per dollar has fallen behind Snowflake and BigQuery for many workloads; Spectrum adds latency for S3 queries; less compelling outside AWS |
| Microsoft Fabric | Microsoft | Cloud (Azure) | Unified SaaS analytics platform: Data Factory, Synapse, Power BI, Data Science, Real-Time Intelligence, OneLake lakehouse; Copilot AI throughout | No | Microsoft's strategic platform combining DWH, lakehouse, BI, and AI engineering in one SaaS offering; OneLake provides unified storage; rapid feature expansion; strong Power BI integration | Newer platform still maturing; some features in preview; best value inside Microsoft ecosystem; migration from Synapse creates transition effort |
| Azure Synapse Analytics | Microsoft | Cloud (Azure) | Unified analytics, Serverless SQL Pool, Dedicated SQL Pool, Spark, Power BI integration; being superseded by Microsoft Fabric as strategic direction | No | Mature enterprise option; strong for existing Azure investments; Synapse Link enables operational analytics without ETL; Serverless SQL is very cost-effective for ad hoc queries | Microsoft shifting focus to Fabric; long-term Synapse roadmap may slow; some features redundant with Fabric; less compelling for new deployments |
| Teradata Vantage | Teradata | On-prem / Cloud | Massively parallel DWH, multi-cloud Vantage, QueryGrid federation, ClearScape Analytics (ML in-DB), NOS for unstructured object data | No | Most mature enterprise DWH for very large mixed workloads; ClearScape Analytics delivers in-database ML; NOS extends to unstructured data in object stores | High total cost of ownership; modernization pace slower than cloud-native peers; legacy architecture limits agility for modern data product patterns |
2.4.3.7 Data Lakehouses and Open Table Formats
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Databricks Lakehouse | Databricks | Cloud (multi-cloud) | Delta Lake open format, Unity Catalog (tables, models, files), MLflow, Delta Live Tables, Photon engine, Genie AI analytics, serverless compute, file governance | Partial (Delta Lake OSS) | Market leader in lakehouse; strongest ML and AI integration of any analytics platform; Unity Catalog governs tables, models, and unstructured files; multi-cloud; active OSS ecosystem | Cost management complex; Delta Lake tuning requires expertise; SQL analytics experience less polished than Snowflake for pure analytics workloads |
| Apache Iceberg | Apache (OSS) | OSS / Multi-engine | Open table format, ACID transactions, schema evolution, time travel, partition evolution, REST catalog specification, multi-engine compatibility | Yes (Apache 2.0) | Emerging dominant open format supported by Snowflake, BigQuery, Databricks, Dremio, Spark, Flink, Trino; reduces vendor lock-in at storage layer; strong governance features | Not a query engine; requires compatible compute engine; REST catalog spec still maturing; migration of existing tables adds effort |
| Delta Lake | Databricks / LF Delta | OSS / Databricks | Open table format (ACID, time travel, schema enforcement), DML operations, UniForm for Iceberg/Hudi interoperability, Change Data Feed | Yes (Apache 2.0) | Native Databricks format with very strong operational track record; UniForm enables multi-format interoperability; Change Data Feed supports CDC downstream patterns | Databricks-native heritage; cross-engine compatibility improving but Iceberg has broader neutral support; UniForm adds overhead |
| Dremio Sonar / Arctic | Dremio | Cloud / On-prem | SQL lakehouse, Iceberg catalog (Nessie/Arctic), query acceleration via reflections, data-as-a-product model, columnar cloud cache | Partial (Nessie OSS) | Strong Iceberg-native platform; query acceleration reflections deliver very high analytical performance without data movement; open lakehouse approach reduces lock-in | Smaller market presence than Databricks or Snowflake; reflections require maintenance; enterprise support less mature at scale |
| Starburst Galaxy | Starburst | Cloud (SaaS) | Managed Trino federated queries across 50+ sources, Iceberg/Delta/Hudi support, data products, role-based access, data mesh architecture support | Partial (Trino OSS) | Best managed federated query engine for multi-cloud and on-premises data access without movement; strong data mesh architecture; Trino OSS core reduces lock-in | Query performance limited by federation overhead for large analytical workloads; data product features still maturing; primarily a query layer, not a storage platform |
| Apache Spark | Apache / Databricks | OSS / Cloud | Unified analytics engine, Spark SQL on Delta/Iceberg/Hudi, streaming and batch in one framework, MLlib, GraphX, unstructured data processing | Yes (Apache 2.0) | Foundational compute engine for virtually all lakehouse workloads; runs on all major clouds and on-premises; handles binary, text, and tabular data; largest big data ecosystem | Operational complexity; JVM tuning required for performance; memory management challenges at scale; not suitable for low-latency OLTP patterns |
| AWS Lake Formation + S3 | AWS | Cloud (AWS) | Data lake on S3, fine-grained access control, Glue catalog integration, Iceberg Tables, transaction support, unstructured file governance via S3 and Macie | No | Foundational AWS lake architecture; Lake Formation fine-grained permissions; broad Iceberg support; governs S3 objects including documents alongside tables | AWS-centric; limited governance UI compared to Databricks Unity or Snowflake Horizon; Lake Formation permission model has a learning curve |
The most significant structural development in analytics storage is the commoditization of the open table format. Apache Iceberg has emerged as the leading neutral standard, now supported natively by Snowflake, BigQuery, Databricks, Dremio, and virtually every major query engine. This dissolves vendor lock-in at the storage layer and shifts competition to compute performance, governance capability, and AI integration. Snowflake and Databricks are in a direct competitive battle for the full analytics platform market; Microsoft Fabric represents the most ambitious consolidation play. All major platforms are extending governance to unstructured assets alongside tables, recognising that the lakehouse must handle documents, images, and model artefacts as well as columnar data.
2.4.4 Governance
Governance encompasses the policies, controls, processes, and tooling that ensure data and AI assets are managed responsibly, remain fit for purpose, comply with regulatory obligations, and are accessible only to those authorized to use them. Effective governance spans the full data lifecycle from ingestion to consumption, and increasingly extends to AI-generated outputs and the models that produce them. This section covers five disciplines that together constitute a comprehensive governance capability: data governance and stewardship, AI governance and model risk, data quality and observability, data reconciliation, and data security and entitlements.
2.4.4.1 Data Governance
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Collibra Data Governance Center | Collibra | Cloud / On-prem | Policy management, stewardship workflows, business glossary, data classification, regulatory mapping (GDPR, CCPA, HIPAA) | No | Gold standard for enterprise governance; comprehensive policy and workflow engine; document governance via DeasyLabs; market-leading reference base | Significant implementation investment and ongoing stewardship effort required; premium pricing; complex for smaller organizations |
| Collibra DeasyLabs | Collibra | Cloud (SaaS) | AI-powered unstructured data governance, document classification, sensitive data policy enforcement in files, SharePoint/S3/NAS governance, GDPR compliance for document stores | No | Purpose-built for unstructured data governance within Collibra ecosystem; AI-driven classification; strong for compliance-driven document governance | Collibra ecosystem dependency; newer product building enterprise references; limited structured data governance capability |
| Informatica Axon Data Governance | Informatica | Cloud / On-prem | Governance program management, business glossary, policies, DQ integration, IDMC unified platform, AI-assisted file and semi-structured asset classification | No | Strong enterprise governance within Informatica suite; AI-assisted classification across structured and semi-structured data; good regulatory mapping | Best value inside Informatica suite; complex standalone deployment; governance UX less modern than Atlan or Collibra Cloud |
| Microsoft Purview Information Protection | Microsoft | Cloud (Azure / M365) | Sensitivity labels, DLP policies, compliance manager, Teams/SharePoint/Exchange governance, AIP for Office files, regulatory compliance templates, M365 audit trails | No | Dominant for M365 and Office document governance; uniquely strong unstructured data policy enforcement; expanding to structured databases | Azure/M365 ecosystem dependency; governance workflow depth for structured data less mature than Collibra; stewardship workflows limited |
| Data Dynamics | Data Dynamics | Cloud / On-prem | Unstructured data governance across NAS, S3, SharePoint, file servers; content classification, retention policy automation, access governance, GDPR and HIPAA compliance for documents and emails | No | Comprehensive unstructured data governance platform; storage and compliance optimization combined; strong for large file-heavy organizations | Primarily unstructured focus; structured database governance limited; less known than Microsoft Purview or Varonis for this use case |
| Ohalo | Ohalo | Cloud (SaaS) | AI-powered unstructured data governance, GDPR/CCPA compliance discovery, automated data subject request fulfilment from documents and emails, retention policy enforcement | No | Excellent AI-powered governance of unstructured data for compliance; strong DSAR automation across document stores; clean user interface | Smaller vendor; primarily compliance-driven; limited suitability as a general-purpose governance platform; structured data governance absent |
| Varonis Data Security Platform | Varonis | Cloud (SaaS) / On-prem | Unstructured data governance, file access analytics, least-privilege automation, SharePoint/Teams/Exchange/NAS policy enforcement, data risk scoring | No | Best-in-class for unstructured data access governance; identifies who can access what files and whether they should; strong insider threat detection | Security-first tool; business glossary and stewardship workflow absent; primarily access governance rather than data definition management |
| BigID | BigID | Cloud (SaaS) | PII discovery and classification across structured and unstructured data, privacy risk scoring, retention policy automation, DSAR workflows, 500+ source connectors | No | Leader in privacy governance across heterogeneous data types; covers databases, files, emails, cloud storage; strong DSAR automation at scale | Primarily privacy and compliance governance; business glossary and stewardship workflows less developed; analytics governance use case limited |
| Alation Governance | Alation | Cloud / On-prem | Trust flags, curation campaigns, stewardship assignments, policy catalog, governance embedded in discovery and catalog workflows | No | Governance through usability; trust flags and usage data drive stewardship naturally; good integration of governance and discovery | Primarily structured data governance; unstructured coverage limited; less comprehensive policy engine than Collibra |
| Atlan Data Governance | Atlan | Cloud (SaaS) | Policy-driven governance, ownership management, classification, PII tagging, Monte Carlo and Soda DQ integration, custom asset governance | No | Modern developer-friendly governance; strong API extensibility; asset-type agnostic policies; growing enterprise adoption | Newer vendor building enterprise track record; governance workflow depth building; less proven for highly regulated industries |
| Securiti.ai | Securiti | Cloud (SaaS) | Data command center, DSAR automation, consent management, AI governance framework, cross-cloud DLP for structured and unstructured data | No | Privacy-first governance; strong DSAR automation; AI governance module relevant for EU AI Act compliance; cross-cloud coverage | Governance-as-security focus; business glossary and stewardship limited; best for privacy compliance programs rather than data management governance |
| Solidatus | Solidatus | Cloud / On-prem | Financial regulatory governance (BCBS239, DORA, MiFID II), data flow modelling, governance mapping for document and process flows, visual lineage-linked policies | No | Specialist in financial services regulatory compliance governance; model-driven approach handles complex cross-system obligations well | Niche financial services focus; not a general-purpose enterprise governance platform; business glossary depth limited |
Modern requirements include automated PII detection across both structured and unstructured data, regulatory compliance mapping, stewardship workflow automation, and federated governance models supporting data mesh domain ownership.
Unstructured data governance is where most enterprises are furthest behind. Microsoft Purview and Varonis address the M365 and file server governance gap that structured data tools have historically ignored. Collibra DeasyLabs, Data Dynamics, and Ohalo are purpose-built for organizations that need to extend formal governance to their document and file estates, which is increasingly a regulatory requirement under GDPR, HIPAA, and the EU AI Act. Governance-as-code approaches, where policies are version-controlled and applied programmatically through APIs, are gaining traction as platform engineering teams take on data governance automation responsibilities.
2.4.4.2 AI Governance
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Fiddler AI | Fiddler AI | Cloud (SaaS) | ML model performance monitoring, explainability (SHAP and LIME), data and prediction drift detection, NLP model monitoring, LLM trust and safety scoring, LLMOps | No | Pioneer in ML model observability; comprehensive explainability capabilities; extending well to LLM trust and safety monitoring; good integration with major ML platforms | Premium pricing; best for organizations with significant ML deployment at scale; LLM monitoring features newer and still maturing compared to core ML observability |
| Arize AI / Phoenix (OSS) | Arize AI | Cloud (SaaS) / OSS | Production ML monitoring, LLM observability (Phoenix OSS), embedding drift analysis, hallucination and relevance tracing, retrieval evaluation for RAG pipelines | Yes (Phoenix Apache 2.0) | Phoenix OSS is excellent for LLM evaluation and RAG tracing; embedding drift is a genuine differentiating capability; strong for organizations building AI pipelines over unstructured documents; fast-growing customer base | Core monitoring for traditional ML requires paid Arize platform; Phoenix OSS requires engineering to deploy; LLM hallucination detection still an emerging science not a solved problem |
| Microsoft Responsible AI Toolkit | Microsoft | Cloud (Azure) / OSS | Responsible AI dashboard (fairness, explainability, error analysis, causal analysis, counterfactuals), RAI Toolbox OSS library, Azure ML integration, Prompt Flow responsible AI checks | Yes (MIT RAI Toolbox) | Most comprehensive open-source Responsible AI toolkit available; Azure ML integration is seamless; covers structured ML and increasingly LLM applications; very well documented | Toolbox is primarily for model developers; operationalising into governance programs requires additional work; LLM governance features less advanced than specialist tools like Credo AI |
| Credo AI | Credo AI | Cloud (SaaS) | AI risk management platform, policy-to-practice governance workflows, EU AI Act compliance mapping and readiness, vendor AI system assessment, AI model registry | No | Best for enterprise AI risk and compliance management programs; EU AI Act readiness is a focused and well-developed strength; good for organizations needing formal AI governance documentation | Less technical depth for model monitoring versus Fiddler or Arize; primarily risk management and compliance program focus; smaller vendor with building enterprise references |
| Holistic AI | Holistic AI | Cloud (SaaS) | AI risk auditing, EU AI Act assessment and compliance mapping, bias testing, robustness testing, compliance report generation, AI Act registry support | No | Specialist EU AI Act compliance; comprehensive risk auditing methodology; strong regulatory expertise; good for third-party AI system auditing as well as internal governance | Primarily compliance and audit focus rather than continuous monitoring; smaller vendor; limited to governance use case rather than ML performance monitoring |
| WhyLabs / whylogs | WhyLabs | Cloud (SaaS) / OSS | Data and model monitoring, whylogs OSS statistical profiling library, LLM output monitoring, data drift and model drift detection, LLM guardrails and safety | Yes (whylogs Apache 2.0) | whylogs OSS library is becoming a widely adopted standard for statistical profiling; strong statistical foundation for drift detection; LLM output monitoring and guardrails growing; good for ML and AI pipelines | Full platform monitoring requires WhyLabs paid service; LLM governance less comprehensive than Credo AI for compliance programs; primarily technical monitoring rather than business-level risk management |
| IBM Watson OpenScale / AI Fairness 360 | IBM | Cloud / On-prem / OSS | AI Fairness 360 OSS toolkit (50+ fairness metrics), explainability, automated bias detection, Cloud Pak for Data integration, regulatory compliance reporting | Yes (AI Fairness 360 Apache 2.0) | Strong academic heritage in AI fairness; AI Fairness 360 OSS toolkit widely used in research and compliance teams; IBM Cloud enterprise integration; comprehensive fairness metrics | UI and platform less modern than commercial competitors; primarily IBM Cloud ecosystem; commercial product positioning less clear; primarily structured ML focus |
| Arthur AI | Arthur AI | Cloud (SaaS) | Bias and fairness monitoring, ML performance monitoring, explainability, NLP and CV model support, Arthur Shield for real-time LLM content safety guardrails | No | Comprehensive fairness and performance monitoring; Arthur Shield adds practical real-time LLM safety guardrails; good for organizations needing both ML and LLM governance in one platform | Smaller vendor with building enterprise references; Shield LLM guardrails newer feature; pricing significant for full platform adoption |
| Truera | Truera | Cloud (SaaS) / On-prem | Model intelligence platform, root cause analysis for model failures, systematic testing before deployment, performance debugging, NLP and tabular support | No | Strong model debugging capabilities; root cause analysis approach is genuinely differentiating for diagnosing model problems; systematic pre-deployment testing reduces production incidents | Smaller vendor; primarily ML model debugging focus; LLM governance capabilities less developed; limited enterprise references compared to DataRobot or Fiddler |
| Scale AI (Evals) | Scale AI | Cloud (SaaS) | LLM evaluation and benchmarking, RLHF training data collection, red-teaming and safety evaluation, benchmark management, human evaluation at scale | No | Leading LLM evaluation and safety testing platform; critical for responsible LLM deployment; human evaluation at scale is a genuine differentiator for quality assurance; red-teaming capability strong | Primarily LLM evaluation focus; less suitable for traditional ML governance; human evaluation adds significant cost at scale; primarily used by AI product teams rather than enterprise governance |
| Lakera Guard | Lakera | Cloud (SaaS) / API | Real-time LLM prompt injection detection, jailbreak prevention, PII in prompt detection, content moderation for AI apps, data leakage prevention for LLM outputs | No | Specialist LLM security layer; prompt injection protection is increasingly critical for production AI applications; lightweight API integration; growing adoption in enterprise LLM deployments | Primarily LLM security focus; not a full AI governance platform; newer vendor building enterprise references; effectiveness against novel prompt injection techniques requires continuous updates |
AI governance is transitioning from a voluntary best practice to a regulatory requirement. The EU AI Act, fully applicable from August 2026, mandates conformity assessments, transparency obligations, and human oversight for high-risk AI systems. This is driving organizations to establish formal AI governance programs covering AI system inventory and risk classification, model cards and documentation standards, bias and fairness testing before deployment, continuous monitoring for performance degradation and drift, explainability for decision-making systems, and incident response processes for AI failures.
LLM applications introduce new governance challenges that traditional model monitoring tools were not built for: hallucination detection, prompt injection protection, output moderation, and tracing decisions back to training data and prompts. Tools like Lakera Guard (prompt injection), Arize AI Phoenix (LLM tracing and RAG evaluation), and Scale AI Evals (safety testing) are filling these gaps. The intersection with unstructured data governance is significant: AI systems that process documents and generate outputs based on unstructured content need governance frameworks that trace outputs back through the document pipeline to original source material.
2.4.4.3 Data Quality and Observability
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Monte Carlo | Monte Carlo | Cloud (SaaS) | ML-based anomaly detection, data observability across 40+ sources, lineage, incident management, Slack/PagerDuty alerts, data products monitoring | No | Pioneer and market leader in data observability; strong ML anomaly detection catches issues no manual rule would anticipate; broad connector set | Premium pricing; primarily structured/tabular data; LLM and unstructured quality monitoring limited; requires dedicated configuration time |
| Soda | Soda | OSS / Cloud (SaaS) | SodaCL declarative quality checks, no-code and code modes, 50+ integrations, business-user-friendly DQ, incident tracking, data contracts support; ML-based anomaly detection via Metrics Monitoring across any calculated metric without manual threshold configuration; Contract Autopilot and Copilot for automated check generation | Yes (Soda Core OSS) | Outstanding declarative approach makes DQ accessible to both engineers and business users; SodaCL is readable and maintainable; strong incident management; data contract integration is market-leading; active OSS community and excellent commercial support | Configuration overhead for large and complex environments; smaller ecosystem of pre-built integrations compared to Monte Carlo; enterprise pricing can be a barrier for smaller teams |
| Great Expectations (GX) | Great Expectations / GX Cloud | OSS / Cloud | Expectations-based validation framework, data docs auto-documentation, 40+ backends, dbt/Airflow integration, CI/CD native, GX Cloud collaboration layer | Yes (Apache 2.0) | De facto standard for code-first DQ in Python pipelines; 10k+ GitHub stars; GX Cloud adds team collaboration and scheduling; excellent documentation | Less accessible for non-engineers; monitoring and alerting require GX Cloud or custom work; anomaly detection requires additional tools beyond static checks |
| dbt Tests | dbt Labs | OSS / Cloud | Schema tests, custom tests, dbt-expectations package, source freshness checks, compile-time validation, dbt Cloud scheduling | Yes (Apache 2.0) | Essential lightweight DQ for SQL ELT pipelines; zero additional tooling for dbt users; column-level assertions compile alongside transforms | Static rule-based only; no anomaly detection; coverage limited to dbt models; alerting and observability require additional tools |
| AWS Glue Data Quality | AWS | Cloud (AWS) | Managed DQ rules in AWS Glue ETL, DQDL rule language, DQ scores published to Glue Data Catalog, CloudWatch alerts, native S3/Redshift/Glue integration | No | Zero-ops cloud-native DQ for AWS Glue pipelines; no separate tool required; DQ scores surfaced in Glue Catalog; pay-per-use pricing | Limited to AWS Glue pipelines; rule-based only, no ML anomaly detection; limited cross-source coverage outside AWS ecosystem |
| Azure Data Factory / Purview DQ | Microsoft | Cloud (Azure) | Data quality rules in ADF mapping data flows, Purview data quality assessments, DQ scores in data catalog, Azure Monitor integration | No | Integrated DQ across Azure data estate; DQ scores visible in Purview catalog; good for Azure-centric organizations with ADF pipelines | Azure-centric; cross-cloud and on-premises coverage limited; ML anomaly detection not yet as mature as Monte Carlo or Bigeye |
| Google Dataplex DQ | Cloud (GCP) | Managed DQ rules in Dataplex, BigQuery-native execution, DQ results in Data Catalog, scheduled and on-demand scanning, CloudDQ open-source framework | Partial (CloudDQ OSS) | Excellent BigQuery and GCS integration; DQ results directly in Dataplex catalog; CloudDQ open-source engine for portability; managed scaling | GCP-centric; limited cross-cloud coverage; anomaly detection less advanced than specialist observability tools | |
| Snowflake Data Quality / DQ Monitoring | Snowflake | Cloud (SaaS) | Native data metric functions, freshness and volume monitoring, custom DQ checks, Horizon Catalog DQ scores, Streamlit-based DQ dashboards | No | Zero-friction DQ for Snowflake users; native functions execute in-warehouse; DQ results surfaced in Horizon Catalog; no data movement required | Snowflake-only; limited ML anomaly detection; requires SQL skills for custom checks; not a replacement for standalone observability tools |
| Databricks Lakehouse Monitoring | Databricks | Cloud | Managed monitoring for Delta tables, statistical drift detection, schema monitoring, profile dashboards, Unity Catalog DQ integration, custom metrics | No | Excellent for Databricks-centric estates; covers structured and ML feature data; Unity Catalog integration surfaces DQ scores with lineage | Databricks-only; ML drift detection is primary focus rather than rule-based quality; general-purpose DQ less deep than Monte Carlo |
| Acceldata Data Observability Platform | Acceldata | Cloud (SaaS) / On-premises / Hybrid | Data pipeline observability across Spark, Hadoop, Kafka, and cloud warehouses; compute and infrastructure health monitoring; data quality checks at pipeline and dataset level; cost and resource utilization analytics; anomaly detection with configurable alerting; integrations with Databricks, Snowflake, and major cloud platforms | No | Uniquely combines data quality observability with compute and infrastructure reliability in a single platform; strong in complex hybrid and on-premises environments; proven at scale in financial services and telecoms; deep Spark and Hadoop coverage that cloud-native SaaS tools do not match | Less focused on business-user-facing data quality than Monte Carlo or Soda; infrastructure angle blurs positioning relative to pure data quality tools; smaller brand recognition than category leaders; on-premises capabilities less frequently updated as roadmap shifts toward cloud |
| Revefi Data Operations Platform | Revefi | Cloud (SaaS) | AI-driven anomaly detection across data pipelines and warehouse metrics; automated root cause analysis with natural language explanations; cost and query performance optimization for Snowflake and Databricks; spend attribution at team, pipeline, and query level; automated incident routing to data owners; integrations with dbt, Airflow, Fivetran, and major cloud warehouses | No | AI-native root cause analysis reduces mean time to resolution significantly; cost optimization layer delivers measurable ROI beyond observability alone; natural language incident explanations accessible to non-engineering stakeholders; tight integration with Snowflake and Databricks makes it immediately actionable in modern data stacks | Early-stage vendor with limited enterprise track record; strongest coverage is Snowflake and Databricks — heterogeneous or legacy stacks get less value; no on-premises deployment; automated remediation is advisory rather than executable; limited presence outside North America |
| Datactics | Datactics | Cloud / On-prem | Data quality management, profiling, matching and deduplication, cleansing, DQ rule studio, reference data management, regulatory DQ for financial services | No | Strong regulatory DQ capability; purpose-built for financial services data quality requirements; good matching and deduplication for entity data | Smaller vendor; primarily financial services focus; less known than Informatica or IBM for broader enterprise DQ; limited cloud-native deployment options |
| Bigeye | Bigeye | Cloud (SaaS) | Automatic ML threshold learning, freshness/volume/schema monitoring, root cause analysis, warehouse-native push-down execution, 30+ source connectors | No | Strong automated monitoring with minimal configuration; warehouse-push-down reduces latency and cost; good root cause analysis tooling | Smaller vendor building enterprise scale; less deep analyst-facing tooling than Monte Carlo; integration ecosystem still growing |
| Ataccama ONE | Ataccama | Cloud / On-prem | DQ management, profiling, MDM integration, DQ scoring dashboards, governance, automated remediation suggestions, European deployment options | No | Comprehensive DQ plus MDM platform; strong in regulated industries; good remediation workflow; European vendor with EU data residency options | Complex platform to deploy; full value requires MDM and governance adoption; less strong on ML-based anomaly detection |
| Informatica Data Quality (IDMC) | Informatica | Cloud / On-prem | Profiling, parsing, standardization, address validation, DQ dashboards, CLAIRE AI assistance, 500+ source connectors | No | Enterprise DQ leader with deep cleansing; strong address and identity quality; broad source coverage; CLAIRE AI suggestions impressive | Best value inside Informatica suite; expensive standalone; complex deployment; business-user accessibility limited compared to Soda |
| WhyLabs / whylogs | WhyLabs | Cloud (SaaS) / OSS | ML data and model monitoring, whylogs OSS library, data and model drift detection, NLP and computer vision model support, LLM output monitoring | Yes (whylogs OSS) | Best open-source approach for ML pipeline data quality; whylogs library is becoming a standard for statistical profiling; extends naturally to unstructured ML inputs | Primarily ML/AI pipeline quality; structured DQ rule management limited; less suitable as primary warehouse DQ tool |
| Arize AI / Phoenix | Arize AI | Cloud (SaaS) / OSS | Production ML monitoring, LLM output quality (hallucination, relevance, toxicity scoring), embedding drift, tracing, RAG pipeline evaluation | Yes (Phoenix OSS) | Critical for unstructured AI pipeline quality; Phoenix OSS is excellent for LLM evaluation and RAG tracing; hallucination detection is market-leading | Primarily AI/LLM quality focus; not a structured data DQ tool; requires ML engineering expertise to deploy effectively |
Data quality and observability has matured from a niche concern into a first-class discipline within the modern data platform. The category spans a wide spectrum: from schema validation and null checks run as dbt tests, through statistical anomaly detection on live data pipelines, to full infrastructure and compute reliability monitoring. The broadening of scope reflects a practical reality — a data product can fail its consumers not just because the data is wrong, but because the pipeline delivering it is slow, the warehouse query is unoptimized, or an upstream job silently dropped rows without raising an alert.
The market leaders — Monte Carlo, Soda, and Great Expectations — have established the core vocabulary of data observability: freshness, volume, distribution, schema, and lineage-based impact assessment. Cloud platform vendors have followed with native capabilities: Databricks Lakehouse Monitoring, Snowflake Data Quality Monitoring, and Google Dataplex DQ reduce the need for a separate tool for organizations already committed to a single platform, though they lack the cross-platform visibility that independent tools provide.
A newer cohort of vendors is expanding the category in two directions. Acceldata addresses the infrastructure and compute layer alongside data quality, providing a unified view of pipeline health, resource utilization, and data reliability. Revefi approaches the problem from an AI-operations angle, using machine learning to automate root cause analysis, route incidents to owners, and surface cost optimization opportunities. The most important design decision in this category remains coverage versus depth: organizations with a dominant platform should evaluate native capabilities first; those with multi-cloud or heterogeneous stacks will typically find independent observability tools justify their cost through broader coverage and faster cross-system incident correlation.
2.4.4.4 Data Reconciliation
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| AutoRek | AutoRek | Cloud / On-prem | Financial reconciliation automation, multi-source matching, exception management, regulatory reporting (T2S, EMIR, CSDR), AI-assisted exception handling | No | Market leader in financial services reconciliation; highly configurable matching rules; strong regulatory reporting output; proven at tier-one banks | Financial services specialist; general-purpose data engineering reconciliation not a primary use case; implementation projects can be lengthy |
| SmartStream TLM | SmartStream | On-prem / Cloud | Enterprise reconciliation, cash/position/trade matching, SWIFT integration, AI-assisted exception handling, intraday reconciliation | No | Deep capital markets heritage; strong for complex financial instrument reconciliation; good intraday capability for near-real-time requirements | Primarily capital markets and post-trade; less suitable for non-financial reconciliation; legacy architecture in on-prem deployments |
| Gresham Clareti | Gresham Technologies | Cloud / On-prem | Enterprise data integrity and reconciliation, multi-source matching, exception workflow, real-time reconciliation, regulatory controls, Clareti Platform | No | Strong in financial services data integrity; real-time capability is a genuine differentiator; comprehensive regulatory controls framework; proven track record in banks and asset managers | Primarily financial services focus; smaller market presence than AutoRek and SmartStream; primarily UK and European reference base |
| IntelliMatch | SS&C Technologies | On-prem / Private Cloud | Enterprise reconciliation for cash, securities, and trade matching, multi-entity and multi-currency support, configurable matching rules, exception management and workflow, regulatory reporting, SWIFT and custodian statement integration, intraday reconciliation capability | No | Long-established platform with deep capital markets pedigree; SS&C ownership provides stability and broad financial services distribution; strong for custody and fund administration reconciliation where SS&C already has platform relationships; proven at scale across tier-one asset managers and fund administrators | Primarily fund administration and custody focus rather than broader financial services reconciliation; less commonly seen outside the SS&C ecosystem; modernization pace slower than cloud-native competitors; UI and developer experience dated compared to AutoRek or Gresham Clareti; limited appeal for organizations not already in the SS&C product family |
| FIS Integrity | FIS | Cloud / On-prem | Enterprise reconciliation for cash, nostro, securities, and derivatives, configurable multi-source matching, exception workflow and ageing management, SWIFT and custodian connectivity, regulatory reporting support, intraday and end-of-day processing, integration with FIS broader banking platform suite | No | Deep capital markets and banking heritage from SunGard lineage; very large installed base across tier-one banks and custodians; broad instrument coverage across asset classes; strong for nostro and cash reconciliation at high transaction volumes; FIS ecosystem integration is an advantage for organizations running other FIS products | Legacy on-premises architecture with limited cloud-native deployment path; modernisation has been slower than the market; FIS ownership has brought stability but not significant product innovation in recent years; UI and developer tooling dated relative to AutoRek and Gresham Clareti; specialist FIS skills increasingly hard to source |
| ReconArt | ReconArt | Cloud (SaaS) | Multi-entity reconciliation, configurable matching rules, exception management, ERP integrations, intercompany reconciliation | No | Strong mid-market option; good balance of capability and ease of use; broader industry applicability beyond financial services | Less deep capital markets capability than AutoRek or SmartStream; enterprise scalability limits compared to tier-one platforms |
| Informatica Data Validation | Informatica | Cloud / On-prem | Automated source-to-target validation, row count, aggregate, and statistical comparison, migration quality assurance, IDMC integration | No | Enterprise-grade migration and ETL validation; integrated within Informatica IDMC; strong for large-scale data migration quality assurance | Best value inside Informatica ecosystem; limited financial reconciliation workflow; not a replacement for specialist reconciliation tools |
| Datafold (Diff) | Datafold | Cloud (SaaS) | Column-level data diffing between environments, migration validation, pipeline regression testing, dbt PR data diffs | No | Excellent technical reconciliation for data engineering teams; unique regression testing approach for pipeline changes; very strong dbt integration | Technical data reconciliation only; no financial instrument matching, exception workflow, or regulatory reporting; limited non-engineer accessibility |
| Great Expectations (custom) | OSS | OSS | Custom expectation suites comparing source and target datasets, aggregate reconciliation checks, integration with pipeline tools | Yes (Apache 2.0) | Flexible and free; can implement source-to-target reconciliation logic; large community; good CI/CD integration | Requires significant custom engineering to operationalise reconciliation workflows; no exception management or regulatory reporting out of the box |
| Soda | Soda | Cloud (SaaS) / Self-hosted | Cross-data-source reconciliation checks; row count and aggregate value comparison across systems; scheduled reconciliation scans with alerting; integration with dbt and Airflow for pipeline-triggered checks; Metrics Monitoring for threshold-free automated detection | Partial (Soda Core is open source) | Reconciliation is natively supported alongside broader data quality checks, avoiding a separate tool; open-source core lowers barrier to entry; strong integration with modern data stacks; actively used in financial services reconciliation workflows | Less purpose-built for reconciliation than dedicated tools such as AutoRek or SmartStream; lacks the audit trail depth and regulatory reporting features required in capital markets; better suited to operational reconciliation than high-volume financial settlement |
| dbt (tests + artifacts) | dbt Labs | OSS / Cloud | Source freshness checks, row count assertions, cross-environment comparison via dbt artifacts, pipeline-level reconciliation | Yes (Apache 2.0) | Native pipeline reconciliation within dbt workflows; lightweight; zero additional tooling for dbt users; good for ELT reconciliation | Static rule-based only; structured data limited; no financial matching, exception management, or intraday capability |
Enterprise-grade reconciliation requires configurable multi-level matching (exact, fuzzy, aggregate), exception workflow management with SLA tracking, and audit trails suitable for regulatory submission. Financial services organizations increasingly demand intraday reconciliation enabled by streaming architectures, and both AutoRek and Gresham Clareti have invested in real-time capabilities to meet this need. For migration validation and engineering-level reconciliation, Datafold and Great Expectations are more appropriate than financial reconciliation platforms. The two use cases — financial data integrity and technical pipeline validation — have fundamentally different requirements and tools and should be assessed separately.
2.4.4.5 Data Security and Entitlements
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Immuta | Immuta | Cloud (SaaS) / On-prem | Policy-as-code data access control, ABAC, dynamic data masking, row-level security, native integration with Snowflake, Databricks, Redshift, BigQuery | No | Leading data access governance for cloud DW and lakehouse; policy-as-code scales across thousands of datasets without per-dataset configuration; structured data focus is very strong | Primarily structured data; file and document access governance limited; high cost at enterprise scale; best value when multi-platform coverage justifies centralized policy |
| Privacera | Privacera | Cloud (SaaS) / On-prem | Unified data access governance, Apache Ranger-based, multi-cloud, PII discovery and masking, compliance automation, fine-grained access policies | Partial (Ranger OSS) | Founded by Ranger creators; strong OSS heritage; enterprise policy management across cloud DW, Spark, and Databricks; good audit trail capabilities | Less modern UI than Immuta; Ranger heritage can feel heavyweight; primarily structured data access; cloud-native capabilities building |
| AWS Lake Formation | AWS | Cloud (AWS) | Column, row, and cell-level permissions on S3 data, tag-based access control, cross-account catalog sharing, fine-grained audit logging, S3 object governance | No | Native AWS data lake security; tag-based access control (TBAC) is essential for AWS data mesh patterns; governs both structured tables and S3 objects | AWS-only; cross-cloud policy consistency not supported; permission model has a learning curve; less business-friendly than Immuta for policy authoring |
| Microsoft Purview Data Policies | Microsoft | Cloud (Azure / M365) | DevOps and reader policies, sensitivity label-driven enforcement, DLP across M365 and Azure, Teams and SharePoint access policies, AIP for Office files | No | Unrivalled for unstructured data DLP; covers Office files, emails, Teams messages alongside structured databases; regulatory templates for GDPR and HIPAA built in | Azure/M365-centric; structured data policy depth less mature than Immuta; cross-cloud DLP limited; governance workflow for stewardship less developed |
| Snowflake Horizon | Snowflake | Cloud (SaaS) | Role-based and attribute-based access, dynamic data masking, row access policies, column-level security, unified Horizon governance layer, tagging-driven policies | No | Native Snowflake security with zero added infrastructure; Horizon governance layer adds unified policy management across the platform; excellent masking capability | Snowflake-only; cross-platform policy enforcement requires additional tools; not a replacement for enterprise-wide data access governance platforms |
| Databricks Unity Catalog | Databricks | Cloud (SaaS) | Unified governance for data and AI assets, fine-grained ACLs, attribute-based access, column masking, audit logs, file-level security for Delta and object storage | No | Comprehensive security covering tables, models, features, notebooks, and files within Databricks; AI asset governance is uniquely capable; audit logs are comprehensive | Databricks-only; cross-platform policy management requires integration with Immuta or Privacera; primarily Databricks ecosystem value |
| BigID | BigID | Cloud (SaaS) | Data discovery and classification across 500+ source types, PII inventory for structured and unstructured data, privacy risk scoring, DSAR automation, retention policy | No | Leader in data privacy intelligence across structured and unstructured sources; finds sensitive data in files, emails, databases; strong DSAR automation at enterprise scale | Primarily a discovery and privacy tool; active enforcement (masking, blocking) requires integration with Immuta or cloud-native controls; not a real-time access gateway |
| Varonis Data Security Platform | Varonis | Cloud (SaaS) / On-prem | Unstructured data access intelligence, file system and SharePoint/Teams/Exchange security, threat detection, UEBA, least-privilege automation for file access | No | Best-in-class for unstructured data security; understands who has access to which files, folders, and Teams channels; UEBA detects abnormal access patterns for insider threat | Primarily unstructured data access governance; structured database ABAC not the strength; higher cost for full platform deployment |
| Satori Data Security | Satori | Cloud (SaaS) | Data access controller as proxy, universal dynamic masking, self-service data access requests, audit logging, BYOC model, multi-cloud masking without data movement | No | Modern lightweight data security proxy; good for teams needing cross-cloud dynamic masking without heavy platform investment; self-service access requests improve user experience | Newer vendor building enterprise scale references; proxy architecture adds latency; limited metadata and governance beyond access control |
| Securiti.ai | Securiti | Cloud (SaaS) | AI-powered PII discovery across structured and unstructured data, consent management, DSAR automation, AI governance module, cross-cloud DLP for files and databases | No | Comprehensive privacy and security platform; AI-native discovery covers databases, files, emails, and cloud storage; AI governance module for EU AI Act compliance | Primarily privacy and compliance governance; business glossary and stewardship limited; pricing can be significant at full enterprise deployment |
| Cyera / Laminar (Palo Alto) | Cyera / Palo Alto | Cloud (SaaS) | Cloud data security posture management (DSPM), continuous data discovery, cloud misconfiguration detection for data stores, risk prioritization, sensitive data exposure alerts | No | Emerging DSPM category leader; Laminar acquired by Palo Alto Networks; continuous cloud-native posture monitoring catches new data exposure risks automatically | Newer category with building enterprise references; DSPM is complementary to access governance tools rather than a replacement; limited on-premises coverage |
| Apache Ranger | Apache (OSS) | OSS / On-prem | Fine-grained access control for Hadoop ecosystem (HDFS, Hive, HBase, Kafka, Spark), centralized policy management, audit logging | Yes (Apache 2.0) | Foundational security for Hadoop and Cloudera deployments; completely free; Privacera extends it to cloud platforms; large existing installed base | Hadoop-era architecture; cloud-native deployments require Privacera or similar wrapper; limited dynamic masking compared to modern alternatives |
Data security has shifted from perimeter-based to data-centric, with fine-grained access enforcement as close to the data as possible. The Data Security Posture Management (DSPM) category, pioneered by Cyera and Laminar, provides continuous visibility into where sensitive data lives, who has access, and where it is over-exposed. A particularly important area is unstructured data security. Most organizations have structured database access tightly controlled while the same sensitive data lives in spreadsheets on SharePoint, PDFs in S3, and emails in Exchange with far weaker controls. Varonis and Microsoft Purview address this gap directly. Dynamic data masking that responds to user attributes and query context in real time, combined with AI-assisted PII discovery to handle continuous growth of new sensitive data assets, are the two capabilities that most organizations still need to mature.
2.4.5 Data Operations Management
Data operations management covers the run-time oversight of data pipelines and platforms: scheduling and coordinating workflow execution, tracking how data assets are used across the organization, and managing the lifecycle of data quality incidents and issues. Effective operations management bridges engineering and business stakeholders, making pipeline health, data usage patterns, and outstanding data issues visible and actionable through a shared operational view.
2.4.5.1 Pipeline Orchestration
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Apache Airflow | Apache (OSS) / Astronomer | OSS / Cloud (Astronomer, MWAA, Composer) | DAG-based orchestration, Python-native, 1000+ operators, dynamic DAGs (Airflow 2.x), TaskFlow API, rich monitoring UI, KEDA-based autoscaling | Yes (Apache 2.0) | De facto standard with massive ecosystem; 35k+ GitHub stars; Astronomer adds enterprise SLA management, SSO, and observability; managed on all major clouds | Scheduler architecture creates performance bottlenecks at high DAG counts; DAG parsing overhead at scale; Python-first design limits accessibility to non-engineers; no native asset orientation |
| Dagster | Elementl / Dagster | OSS / Cloud (Dagster+) | Asset-oriented orchestration, software-defined assets, type-safe ops, deep lineage integration, dbt and Spark native support, Dagster+ managed service | Yes (Apache 2.0) | Most architecturally modern approach; asset-centric model aligns naturally with catalog and governance tools; excellent dbt integration; built-in lineage and observability; strong type safety | Steeper learning curve than Airflow for teams coming from traditional pipeline thinking; smaller community than Airflow; Dagster+ pricing for managed service |
| Prefect | Prefect | OSS / Cloud (Prefect Cloud) | Python-native workflows, dynamic tasks, hybrid push/pull execution model, deployments, Prefect Cloud UI, AI observability, native async support | Yes (Apache 2.0) | Modern and Pythonic; excellent developer experience; hybrid execution model is flexible for mixed cloud and on-premises workloads; Prefect Cloud has very good observability UI | Asset-oriented model less developed than Dagster; community smaller than Airflow; paid cloud required for full feature set |
| dbt Cloud | dbt Labs | Cloud (SaaS) | Scheduling, CI/CD for dbt models, browser IDE, Semantic Layer, metadata API, Explorer lineage visualization, dbt Cloud orchestration hooks, job run monitoring | Partial (dbt-core OSS) | Essential managed orchestration for dbt; best-in-class for ELT pipeline management; Explorer provides good lineage; Semantic Layer enables consistent metric definitions across tools | Limited to dbt workloads; broader orchestration (Spark, Python, ML jobs) requires integration with Airflow/Dagster; CI/CD beyond dbt needs additional tooling |
| Mage.ai | Mage | OSS / Cloud | Modern orchestration with notebook-style interactive development, built-in streaming pipeline support, LLM and AI pipeline orchestration, real-time and batch in one tool | Yes (Apache 2.0) | One of the first orchestrators built with AI pipeline orchestration as a first-class concern; excellent developer experience; handles batch, streaming, and ML pipelines natively | Younger project; smaller community than Airflow or Dagster; enterprise features still building; production track record at very large scale less established |
| Kestra | Kestra (OSS) | OSS / Cloud | YAML-first orchestration, 500+ plugins, event-driven triggers, Kafka and Pulsar integration, multi-tenant, Git-native workflows, plugin development framework | Yes (Apache 2.0) | Modern event-driven orchestration with strong plugin ecosystem; YAML-first is accessible to non-Python teams; infrastructure-as-code native design; excellent Kafka and event-driven support | Younger project; community and ecosystem still building; Python-heavy teams may prefer Dagster or Prefect; limited enterprise references compared to Airflow |
| AWS Step Functions | AWS | Cloud (AWS) | Serverless workflow orchestration, visual State Machine designer, Express/Standard workflows, Lambda/ECS/Glue/SageMaker integration, error handling, retries | No | Native AWS serverless orchestration; eliminates all ops overhead; very strong integration with AWS services; visual designer accessible to non-engineers; pay-per-transition pricing | AWS-only; limited cross-cloud portability; visual designer less capable for complex data engineering DAGs; Python data engineering experience preferred elsewhere |
| Azure Data Factory Pipelines | Microsoft | Cloud (Azure) | Visual pipeline orchestration, 100+ triggers, monitoring dashboard, debug mode, Azure Monitor integration, Fabric Pipelines evolution | No | Mature Azure-native orchestration; good visual experience for non-engineers; strong monitoring; Fabric Pipelines evolving as the strategic orchestration layer for Microsoft | Azure-centric; complex Python and Spark orchestration less elegant than Airflow; migrating to Fabric Pipelines adds transition effort |
| Databricks Workflows | Databricks | Cloud (Databricks) | Job orchestration within Databricks, multi-task jobs, Delta Live Tables pipeline triggers, serverless compute, cluster policies, cost tracking, Unity Catalog integration | No | Best orchestration for Databricks-centric pipelines; deep Unity Catalog and MLflow integration; serverless compute simplifies job management; cost monitoring built in | Databricks-only scope; cross-platform orchestration requires integration with Airflow or Dagster; limited event-driven triggering outside Databricks ecosystem |
Apache Airflow remains the dominant orchestration platform by adoption, but Dagster and Prefect are gaining significant ground with better developer experiences and more modern architectures. The key conceptual shift, best exemplified by Dagster, is from pipeline-oriented orchestration (defining code execution order) to asset-oriented orchestration (defining the data assets that should exist and their upstream dependencies). This asset-centric model aligns naturally with data catalogs, lineage tracking, and data quality monitoring.
Mage.ai is notable for being one of the first orchestration tools built with LLM and AI pipeline orchestration as a first-class concern. As AI workloads become a larger share of data engineering work, orchestrators will need to natively manage GPU cluster allocation, model training jobs, prompt chains, and vector indexing pipelines alongside traditional SQL and Spark jobs.
2.4.5.2 Usage Analytics
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Atlan Usage Analytics | Atlan | Cloud (SaaS) | Asset popularity scoring, query frequency tracking, top users and consumers per asset, downstream impact analytics, data product adoption metrics, BI tool query integration | No | Native to Atlan catalog; surfaces asset-level usage without additional tooling; popularity signals inform governance prioritization; well-integrated with catalog workflows | Requires Atlan as primary catalog; usage data quality depends on integration depth with warehouse and BI tools; standalone deployment not available |
| Alation Analytics | Alation | Cloud / On-prem | Query log mining to surface asset usage frequency, crowd-sourced popularity signals, top assets and users, stewardship workflow triggers based on usage, data culture metrics | No | Usage-driven catalog governance is Alation's founding principle; popularity scores are natively integrated into catalog search ranking; behavioral analytics inform stewardship campaigns | Primarily structured data usage; BI and report usage less comprehensive; on-prem version adds operational overhead |
| Monte Carlo (Usage + Observability) | Monte Carlo | Cloud (SaaS) | Table and dashboard usage tracking, lineage-linked usage impact analysis, query cost attribution, freshness monitoring with usage context, data product adoption metrics | No | Strong usage-and-observability combination; ties quality events to usage impact; downstream consumer alerting when upstream assets degrade; query cost attribution for FinOps | Premium pricing; primarily observability tool with usage analytics as a component rather than primary focus; full value requires broad source integration |
| Tableau Server / Cloud Admin Views | Salesforce | Cloud / On-prem | Workbook and data source usage, view counts, user engagement metrics, performance dashboards, stale content identification, site activity reporting | No | Native admin visibility for Tableau deployments; no additional tooling required; good for understanding BI asset adoption and identifying content candidates for archival | Tableau-only; not integrated with upstream data platform usage; limited cross-tool usage analytics for heterogeneous BI landscapes |
| Power BI Admin / Fabric Capacity Metrics | Microsoft | Cloud (Azure / M365) | Usage metrics per report and dashboard, workspace consumption, capacity utilization dashboards, Fabric admin monitoring, Microsoft 365 audit logs for data access | No | Comprehensive Power BI and Fabric usage analytics; Capacity Metrics app provides detailed resource utilisation; Microsoft 365 integration traces usage across the Microsoft data estate | Microsoft-centric; cross-platform usage analytics not available; technical metrics focus over business-facing data product adoption metrics |
| Secoda Data Observability and Usage | Secoda | Cloud (SaaS) | Catalog with integrated usage analytics, query frequency and recency, downstream dependency usage, data product adoption, stale content detection, usage-driven documentation prioritization | No | Modern catalog with strong usage analytics out of the box; fast deployment; AI-assisted documentation enrichment tied to usage priorities; good for growing data teams | Newer vendor building enterprise references; governance workflow depth less than Collibra; primarily mid-market positioning |
| dbt Cloud Usage and Exposure | dbt Labs | Cloud (SaaS) | Model run frequency and timing, exposure tracking (which BI tools consume which models), source freshness, job cost attribution, Explorer visualization of model usage | Partial (dbt-core OSS) | Native usage visibility for dbt model consumers; exposure tracking ties SQL models to downstream BI content; source freshness tracking as a usage proxy; integrated with catalog metadata | Limited to dbt model usage; broader data asset usage outside dbt ecosystem not covered; monitoring dashboard requires dbt Cloud subscription |
| Splunk Platform | Splunk (Cisco) | Cloud (SaaS) / On-prem | Ingestion and indexing of query logs, access logs, and audit trails from data platforms; real-time search and alerting over usage events; custom dashboards for query frequency, user activity, and failed access patterns; correlation with security and infrastructure events | No | Organizations already running Splunk for security and operations can extend coverage to data platform usage at minimal additional effort; event-level granularity is unmatched for forensic and compliance use cases; strong for detecting anomalous access patterns and correlating data usage with security incidents | Not purpose-built for data governance usage analytics; no native understanding of data assets, ownership, or data products; building meaningful asset-level popularity scores requires significant custom work; does not integrate with data catalog stewardship workflows; licensing cost at enterprise scale is significant |
Usage analytics has evolved from a nice-to-have audit log into an essential input for data platform operations. Three distinct use cases drive adoption: governance prioritisation (focusing stewardship effort on assets that are most used), FinOps (understanding which tables and queries are driving cloud compute costs), and data product management (tracking adoption of published data products by downstream consumers). The most mature implementations embed usage signals directly into catalog search ranking, so that frequently accessed and recently used assets surface higher in discovery, creating a virtuous cycle where good data becomes more discoverable and governance effort follows usage. Organizations should expect usage analytics capabilities to be native to their chosen data catalog platform rather than procuring a separate tool for this purpose.
2.4.5.3 Data Issue Management
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Monte Carlo Incidents | Monte Carlo | Cloud (SaaS) | Automated incident creation from anomaly detection, Slack and PagerDuty integration, incident assignment and SLA tracking, root cause analysis, downstream impact assessment, incident history | No | Best integrated incident management for data observability; anomaly-to-incident workflow is seamless; downstream impact analysis identifies affected consumers automatically; strong Slack integration for data team workflows | Premium pricing; incident management is embedded within observability platform, not a standalone tool; full value requires Monte Carlo as primary observability platform |
| Soda Incidents | Soda | OSS / Cloud (SaaS) | Data quality check failures trigger incidents, configurable alerting channels, incident tracking dashboard, data contracts breach notifications, SodaCL-defined quality expectations as incident sources | Yes (Soda Core OSS) | Incident management natively linked to quality check definitions; data contracts breach creates a clear ownership and accountability model for issue resolution; good balance of OSS and commercial features | Less ML-based anomaly detection than Monte Carlo; incident tracking depth less than dedicated issue management platforms; best for teams with well-defined quality expectations |
| Atlan Issues and Playbooks | Atlan | Cloud (SaaS) | Asset-level issue tracking, custom issue types, playbook automation for remediation, assignment workflows, integration with catalog asset metadata, bulk issue management | No | Issues are natively linked to catalog assets; playbooks enable automating standard remediation steps; bulk management is useful for data migrations and quality campaigns | Requires Atlan as primary catalog; issue management less deep than dedicated platforms; primarily catalog-embedded rather than a standalone incident management system |
| Metaphor Data | Metaphor Data | Cloud (SaaS) | Data catalog with embedded incident and issue tracking, change notification, impact analysis, Slack-based data incident collaboration, data product SLA management | No | Strong incident collaboration model through Slack; impact analysis links incidents to downstream consumers; data product SLA tracking is a differentiating capability | Smaller vendor building enterprise references; catalog depth less than Collibra or Atlan; primarily a catalog with incident features rather than a standalone issue management tool |
| Jira Service Management (Custom) | Atlassian | Cloud / On-prem | Configurable issue tracking and workflow automation for data incidents, SLA policies, escalation rules, integration with observability tools via webhooks and APIs, ITIL-compliant service management | No | Universal adoption for IT service management; highly configurable for data-specific workflows; strong SLA tracking; integrates with PagerDuty, Slack, and observability tools via API; familiar to most engineering teams | Requires custom configuration for data-specific workflows; no native data context (lineage, asset metadata) without additional integration; not purpose-built for data quality incident management |
| Datafold (Pipeline Diff + Alerts) | Datafold | Cloud (SaaS) | Data diffing and regression alerts as incident triggers, dbt PR data diffs, column-level change detection, pipeline regression notifications, environment comparison issues | No | Best for engineering-level data change issue detection; dbt PR data diffs catch issues before they reach production; regression testing is a systematic approach to preventing data incidents | Technical focus; not a full issue lifecycle management platform; limited business user accessibility; no unstructured data coverage |
| ServiceNow (ITSM / Data Operations) | ServiceNow | Cloud (SaaS) | Configurable incident and problem management workflows for data issues, SLA policy enforcement and breach alerting, escalation rules, CMDB integration for data asset context, integration with observability tools via webhooks and REST APIs, audit trails for regulatory compliance | No | Near-universal adoption in enterprise IT means data incidents can be routed into the same system teams already use for infrastructure and application issues; mature SLA management and escalation workflows; strong audit and compliance reporting; good for organizations that want a single system of record for all operational incidents | Not purpose-built for data quality incidents; no native understanding of data lineage, asset ownership, or downstream impact; building data-specific workflows requires custom configuration; data engineers often find ServiceNow heavyweight for day-to-day pipeline issue management compared to Slack-native or catalog-embedded alternatives |
Data issue management sits at the intersection of data observability, data governance, and IT service management. The most common current-state pattern is that observability tools (Monte Carlo, Soda) detect anomalies and alert to Slack, where incidents are managed conversationally without systematic tracking, SLA management, or knowledge retention. This creates three problems: incidents are lost when Slack channels are archived, SLA compliance cannot be demonstrated to regulators or business stakeholders, and the same issues recur because no institutional knowledge is built.
Purpose-built data incident management within observability platforms (Monte Carlo Incidents, Soda Incidents) is the natural first step. Organizations with mature ITSM practices should connect data incidents to existing Jira or ServiceNow processes through integration, maintaining a single system of record for all operational incidents regardless of their origin.
2.5 Distribution and Access
Distribution and access covers the mechanisms through which data consumers — analysts, data scientists, applications, and AI systems — query, retrieve, and work with data. This spans the SQL query engines and data warehouses that power analytics, the virtualisation and semantic layers that present data through a unified logical abstraction, and the search and discovery interfaces that help consumers find and access the data they need. The goal is to make data available to the right consumer, through the right interface, with appropriate performance and access controls.
Note: Data Delivery (2.5.1) leverages the same tooling covered in Section 2.2. See Data Ingestion and Data Delivery.
2.5.2 Search, Query, and Access
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Snowflake (SQL Analytics) | Snowflake | Cloud (SaaS) | Auto-scaling SQL data warehouse, multi-cluster compute, Snowpark Python/Scala/Java, zero-copy cloning, data sharing, Cortex AI SQL functions, Horizon governance integration | No | Market-leading cloud DW performance and ease of use; truly elastic scaling without DBA tuning; Snowpark enables non-SQL workloads; data sharing is a standout capability for cross-organization access; Cortex AI adds native LLM query capability | Per-second compute pricing can escalate; cross-cloud data residency adds complexity; Snowflake lock-in is significant; BI tool query pushdown optimization requires careful configuration |
| Databricks SQL / Databricks Lakehouse | Databricks | Cloud | SQL warehouse for lakehouse queries, serverless SQL, Delta table access, Unity Catalog permissions, Databricks SQL Editor, AI/BI dashboards, natural language to SQL | No | Excellent for lakehouse SQL analytics alongside ML workloads; serverless SQL eliminates cluster management; Unity Catalog integrates access control directly with query engine; natural language SQL is growing | Databricks pricing can be complex; SQL warehouse startup latency vs Snowflake; best value when ML and SQL share the same platform; external tool integration requires configuration |
| Google BigQuery | Cloud (GCP) | Serverless analytics DW, BigQuery ML for in-database ML, BigQuery Omni for multi-cloud, Analytics Hub for data sharing, BQML, column-level security, Dataplex integration | No | Truly serverless at any scale; strong for ad hoc analytics at very large volumes; BigQuery ML brings ML to SQL analysts; Analytics Hub for governed data sharing; excellent Looker and Vertex AI integration | GCP-centric; cost management requires slot reservation or careful query optimization; limited real-time ingestion compared to Snowflake; inter-region data access costs | |
| Azure Synapse Analytics / Microsoft Fabric | Microsoft | Cloud (Azure) | Unified analytics, serverless SQL, dedicated SQL pools, Spark integration, OneLake as universal storage, Fabric workspace for end-to-end pipelines, Direct Lake mode, Purview integration | No | Strong Microsoft ecosystem integration; Fabric is the strategic unified analytics platform direction; OneLake Direct Lake mode eliminates import for Power BI; comprehensive security via Purview and Entra ID | Fabric is still maturing; legacy Synapse and new Fabric create transition complexity; SQL pool pricing for reserved capacity is significant; less compelling for non-Microsoft organizations |
| AWS Athena / Redshift | AWS | Cloud (AWS) | Serverless SQL over S3 (Athena), Redshift managed DW, Redshift Serverless, RA3 storage separation, Redshift Spectrum for S3 federation, Redshift ML | No | Athena provides cost-effective serverless SQL over S3 without cluster management; Redshift remains strong for high-concurrency analytics; Redshift Serverless eliminates capacity planning; deep AWS ecosystem | AWS-centric; Athena performance on complex queries less predictable without careful table partitioning; Redshift less elastic than Snowflake for variable workloads; Athena cost management requires attention |
| Trino / Starburst (Federated Query) | Trino (OSS) / Starburst | OSS / Cloud / On-prem | Federated SQL across 50+ source types, cost-based optimiser, ANSI SQL, Iceberg/Delta/Hudi support, Starburst Galaxy managed service, data mesh data products | Yes (Trino Apache 2.0) | Best open-source federated query engine; avoid data movement by querying sources in place; strong multi-cloud and hybrid deployment; Starburst adds enterprise governance and management layer | Federation overhead for analytical queries; not a storage platform; Starburst Galaxy pricing for managed deployment; query performance tuning requires expertise |
| Elasticsearch / OpenSearch (Enterprise Search) | Elastic / AWS (OSS) | Cloud / OSS | Full-text search and analytics, NLP-enhanced semantic search, vector kNN search, log analytics, APM, security analytics, Kibana/OpenSearch Dashboards | Yes (OpenSearch Apache 2.0) | Core infrastructure for enterprise text search; widely deployed for document retrieval; OpenSearch is fully open-source alternative; vector search for semantic retrieval in AI applications; very broad source indexing | Not a structured analytics database; operational complexity at large scale; index management requires expertise; cost scales quickly with data volume; primarily search rather than complex analytical SQL |
| Data Portal / Access Request (Atlan, Collibra, Alation) | Atlan / Collibra / Alation | Cloud / On-prem | Self-service data access request workflows, access policy enforcement via catalog integration, governed data marketplace, request approval workflows, row and column masking policies in access grants | No | Bridges governance and access: consumers discover data in the catalog and request access through a governed workflow; approval policies enforce governance while enabling self-service; reduces shadow IT access | Requires mature catalog and governance implementation to be effective; workflow depth varies by platform; integrating access approval with actual data access controls requires platform-level integration |
SQL-based access to structured analytics data is dominated by four platforms — Snowflake, Databricks, BigQuery, and Microsoft Fabric — each positioned as a complete analytics and AI platform rather than just a query engine. The choice between them is increasingly made at the organization level based on cloud commitment, ecosystem integration, and commercial relationships rather than pure query performance. For federated access across heterogeneous sources without centralising data, Trino/Starburst remains the most mature open-source option. Enterprise search for unstructured content sits on Elasticsearch or OpenSearch in most organizations, with AI-enhanced semantic search and vector retrieval being rapidly added alongside traditional keyword search. Data access governance — ensuring that discovery and access work together through catalog-embedded access request workflows — is an important emerging capability that brings the governance discipline closer to the moment when a data consumer decides they need access to a specific asset.
2.5.3 Data Virtualization and Semantic Layer
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Denodo Platform | Denodo | Cloud / On-prem | Logical data fabric, 200+ data source connectors, intelligent caching, semantic virtualization layer, AI Query Optimiser, data masking integration | No | Gartner leader in data virtualization; most mature and comprehensive platform; performance achieved through intelligent caching and query pushdown; very broad source coverage including unstructured | Premium pricing makes it primarily enterprise territory; operational complexity; performance for complex multi-source joins can still disappoint without careful caching strategy |
| Dremio Sonar / Arctic | Dremio | Cloud / On-prem | Iceberg-native lakehouse virtualization, Apache Arrow Flight SQL for performance, reflection-based query acceleration, semantic layer, open table format federation | Partial (Nessie OSS) | Best for open lakehouse virtual layer; Arrow-native performance is excellent; Iceberg-first design reduces lock-in; strong data products approach; reflections for pre-computed accelerations | Smaller market than Denodo; reflections require maintenance to stay current; enterprise references building; primarily lakehouse-centric federation rather than broad enterprise data fabric |
| Starburst Galaxy (Trino) | Starburst / Trino (OSS) | Cloud / On-prem | Managed Trino federated SQL across 50+ sources, Iceberg/Delta/Hudi table format support, role-based access control, data products, cost-based query optimiser | Partial (Trino OSS) | Best managed federated query engine; excellent multi-cloud and on-premises source federation; Trino OSS core prevents lock-in; strong data mesh data product support | Federation overhead limits performance for large analytical queries; not a data storage platform; data product governance features maturing |
| TIBCO Data Virtualisation | TIBCO / Cloud Software Group | On-prem / Cloud | Logical data warehouse, composite views, real-time and cached access, semantic modelling, integration with TIBCO BusinessWorks | No | Mature platform with large enterprise installed base; good logical warehouse capabilities; TIBCO integration for complex enterprise architectures; broad source coverage | Modernization pace slower than cloud-native peers; Cloud Software Group ownership adds uncertainty; UI less modern; cloud deployment still building feature parity with on-premises |
| Microsoft Fabric OneLake | Microsoft | Cloud (Azure) | OneLake as universal storage layer with shortcuts to external sources (S3, ADLS), unified SQL virtualisation, Direct Lake mode for Power BI, Fabric integration | No | OneLake shortcuts enable virtual multi-cloud access without data movement; Direct Lake mode for Power BI eliminates import performance bottleneck; strong Microsoft roadmap commitment | Azure-centric; cross-cloud capabilities still maturing; primarily virtualisation within Fabric ecosystem rather than a general-purpose federation layer |
| Google BigQuery Omni | Cloud (GCP) | Cross-cloud SQL queries over AWS S3 and Azure Blob via Omni, BigLake unified storage governance, Analytics Hub for data sharing, federated queries | No | Google's cross-cloud virtualization; Omni enables BigQuery SQL over AWS and Azure data; BigLake adds governance to federated data; strong for multi-cloud analytics | GCP-centric administration; cross-cloud performance and cost unpredictability; primarily a query capability rather than a full data fabric platform | |
| AWS Athena / Redshift Spectrum | AWS | Cloud (AWS) | Serverless SQL over S3 (Athena), Redshift Spectrum for external table federation, cross-account S3 queries, JSON and Parquet format support, Iceberg tables in Athena | No | Lightweight AWS-native virtualization; Athena cost-effective for ad hoc S3 queries; good for unstructured file querying as well as structured; Iceberg support maturing | AWS-centric; limited cross-source federation beyond S3; not a full data fabric; Redshift Spectrum adds latency for mixed DW/lake queries |
| Presto / Trino (OSS) | Meta (Presto) / Trino (OSS) | OSS / On-prem | Federated SQL engine, 30+ native connectors, ANSI SQL compliance, cost-based optimiser, pluggable connector architecture for custom sources | Yes (Apache 2.0) | Foundational OSS federation engine; Trino is the active and well-maintained fork; Starburst provides the enterprise managed version; free for self-managed deployments | Self-managed operations complex at scale; performance requires careful tuning; limited governance and data product features without additional tooling |
Data virtualization is experiencing a renaissance driven by the data mesh pattern, where domain data products must be queryable without centralized physical copies, and the explosion of open table formats, where Iceberg and Delta data can be queried by any engine. Performance remains the central challenge: virtualization adds query overhead that leading platforms address through intelligent caching (Denodo), pre-computed reflections (Dremio), and cost-based push-down optimization. Column-level security enforcement on virtual layers, built-in data lineage through virtual views, and semantic layer capabilities are the modern requirements most organizations still find incompletely addressed in current virtualization platforms.
2.6 BI and Reports
2.6.1 Business Intelligence Platforms
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Microsoft Power BI | Microsoft | Cloud / Desktop | Self-service BI, DAX, Power Query, DirectQuery live mode, AI Insights, Copilot NLQ, Fabric integration, 15k+ custom visuals, paginated reports | No | Market leader by user count; Copilot NLQ is mature and impressive; best integration in Microsoft ecosystem; Fabric alignment positions it as the strategic analytics layer; very competitive total cost of ownership | DAX learning curve for complex measures; large-scale deployments require Fabric Premium; Performance Analyzer needed to diagnose slow reports; best value inside Microsoft stack |
| Tableau | Salesforce | Cloud / Desktop | Best-in-class visual analytics, VizQL proprietary query engine, Tableau Pulse proactive AI insights, Einstein integration, Prep Builder for data prep, embedded analytics, Server and Cloud deployment | No | Gartner MQ leader; strongest visualization depth and flexibility of any BI tool; Tableau Pulse delivers proactive AI-driven insight delivery; excellent embedded analytics; largest data visualization community | Higher total cost than Power BI; Salesforce acquisition has introduced some strategic questions; Hyper engine requires tuning for very large data volumes; data modelling less powerful than Power BI DAX for complex metrics |
| Looker / Looker Studio | Cloud (GCP) | LookML semantic layer, embedded analytics, Looker Studio (free for individual use), BigQuery-native integration, Gemini AI Q&A, data actions, Looker API | No | Unique semantic-layer-first approach ensures metric consistency; Google AI integration maturing rapidly; strong embedded analytics market; Looker Studio free tier democratizes access | LookML requires developer investment to build and maintain; Google ecosystem emphasis; Looker API can be complex for advanced embedded scenarios; not self-service for non-technical users without pre-built content | |
| Qlik Sense / Qlik Cloud | Qlik | Cloud / On-prem | Associative analytics engine, AI-powered Insight Advisor, Qlik AutoML, Active Intelligence with triggered automation, Talend integration for governed data | No | Unique associative model surfaces correlations that filter-driven tools miss; strong self-service for analytical power users; deep enterprise feature set; Talend integration adds governed data pipeline | Associative model has steeper learning curve; UI less modern than ThoughtSpot or Sigma; Talend acquisition integration still maturing; pricing has increased |
| ThoughtSpot | ThoughtSpot | Cloud (SaaS) | Search and AI-driven analytics, SpotIQ automated AI insights, Sage LLM-powered natural language queries, Liveboards, embedded analytics SDK | No | Pioneer in search-based analytics; best-in-class natural language querying accuracy; Sage LLM integration is practical and impressive; excellent embedding capabilities for product analytics | Requires well-modelled data to deliver good NLQ results; less suitable for complex calculated metrics without modelling investment; pricing significant for full enterprise deployment |
| Sigma Computing | Sigma | Cloud (SaaS) | Cloud-native BI with spreadsheet-like interface for analysts, live warehouse data editing, warehouse-native execution, strong collaboration and version control | No | Excellent for Excel-familiar analysts wanting cloud analytics power without learning a new tool; innovative live data editing model; warehouse-native execution avoids data copies | Newer vendor with smaller ecosystem; complex calculated fields less powerful than Power BI DAX; embedded analytics less mature than Tableau or Looker; limited AI features compared to newer tools |
| Clarista | Clarista | Cloud (SaaS) | AI-native analytics and data discovery, natural language questions over business data, automatic insight generation, conversational exploration for non-technical users, contextual recommendations | No | Excellent natural language query experience; very low barrier to analytics for non-technical business users; rapid deployment with minimal data modelling investment; modern LLM-powered interface; makes data genuinely accessible to all staff | Newer entrant building enterprise references; governance and security depth maturing; best suited for business user analytics rather than complex technical reporting; depends on well-structured underlying data sources |
| Apache Superset | Apache (OSS) | OSS / Cloud (Preset) | Open-source BI, SQL Lab for power users, 40+ chart types, RBAC, REST API, dashboard sharing, Preset Cloud managed version | Yes (Apache 2.0) | Best open-source BI alternative; Preset adds managed cloud and enterprise support; active community; no per-seat licensing; SQL Lab gives power users direct query access | Enterprise governance and semantic layer limited compared to commercial tools; AI features require additional tooling; production operations at scale require engineering investment |
| MicroStrategy ONE | MicroStrategy | Cloud / On-prem | Enterprise BI and reporting, HyperIntelligence contextual overlay analytics, mobility platform, AI and bot integration, very large scale report distribution | No | Strong enterprise reporting heritage for very large-scale distribution; HyperIntelligence contextual analytics is differentiating; mobility platform for mobile-first analytics | Strategic distractions in recent years; modernization pace slower than competitors; less compelling for new deployments versus Power BI or Tableau; complex licensing |
| SAP Analytics Cloud | SAP | Cloud (SaaS) | BI, planning, and predictive analytics combined, S/4HANA native integration, SAP Datasphere connectivity, embedded SAP data model, Copilot AI | No | Essential for SAP enterprises; combining BI and planning in one tool is a strong differentiator for budgeting and forecasting; deep S/4HANA integration is unmatched | Limited value outside SAP ecosystem; complex licensing; planning and BI in one tool can feel like a compromise for both use cases versus dedicated tools |
| Metabase | Metabase (OSS) | OSS / Cloud (Pro) | Self-hosted BI, SQL and visual question builder, embedded analytics, simple administration, free open-source tier, Metabase Pro adds SSO and advanced features | Yes (AGPL) | Best lightweight OSS BI for technical teams; quick to deploy; embedded analytics well-supported in the Pro tier; very popular with product analytics and startup teams | Limited enterprise governance; no semantic layer; AI features minimal compared to commercial tools; AGPL license considerations for embedded commercial use |
| Grafana | Grafana Labs | OSS / Cloud | Time-series and operational dashboards, 100+ data source plugins, alerting, Grafana AI assistant, LGTM stack (Loki, Grafana, Tempo, Mimir) | Yes (AGPL) | De facto standard for infrastructure and operational metrics; excellent for real-time and time-series dashboards; growing adoption for business analytics; broad data source coverage | Primarily operational metrics heritage; complex BI reporting less natural than Power BI or Tableau; AGPL licence considerations for embedded commercial use; data modelling minimal |
| IBM Cognos Analytics | IBM | On-premises / Cloud / Hybrid | Self-service reporting and dashboards; AI-assisted data discovery and natural language querying; scheduled and burst reporting; pixel-perfect formatted reports for regulatory and financial output; multi-dimensional OLAP analysis; data modules for semantic layer abstraction; integration with IBM Watson for predictive analytics; enterprise-grade security with row- and object-level access control | No | Exceptionally strong for formatted, paginated financial and regulatory reporting where pixel-perfect output is a hard requirement; mature enterprise security model suits heavily regulated industries; broad deployment flexibility including air-gapped on-premises; large installed base in banking, insurance, and public sector with deep institutional familiarity; robust burst reporting and distribution at scale | Dated UI relative to modern BI tools — self-service experience lags significantly behind Power BI, Tableau, and Looker; high total cost of ownership including licensing, infrastructure, and specialist administration; slow product evolution compared to cloud-native competitors; steep learning curve for casual business users; AI and natural language features are less capable than competitors despite Watson branding; organisations outside the IBM ecosystem rarely choose it for new deployments |
2.6.2 Data Visualization Libraries
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| D3.js | Mike Bostock (OSS) | OSS / JavaScript | SVG and Canvas-based custom visualization, data binding, transitions, layout algorithms, geographic projections, enormous visual flexibility | Yes (ISC) | Gold standard for completely custom web visualization; ultimate visual flexibility; massive community; foundational to many BI tools under the hood; no imposed design conventions | Very high learning curve; significant time investment for production-quality output; not suitable for non-developer users; no built-in chart types |
| Plotly (+ Dash) | Plotly (OSS) | OSS / Dash Enterprise | Python, R, and JavaScript charts, 40+ chart types, Dash for interactive Python web apps, Plotly Express high-level API, 3D charts, financial charts | Yes (MIT) | Best for Python and R data scientists sharing analysis; Dash builds production-grade analytical apps without frontend engineering; excellent 3D and scientific chart support | Dash Enterprise pricing is significant; complex Dash apps require Python engineering; less polished than Tableau for business communications; limited no-code capability |
| Vega / Vega-Lite / Altair | UW IDL (OSS) | OSS / JavaScript | Grammar of graphics for web visualization, declarative JSON specification, Altair Python binding for data scientists, Observable integration | Yes (BSD 3-Clause) | Elegant declarative model; Altair makes it accessible in Python; strong academic and research adoption; Vega-Lite reduces complexity for common charts significantly | Less flexible than D3 for fully custom charts; niche adoption outside academic contexts; JSON specification verbose for complex charts |
| ECharts (Apache) | Apache (OSS) | OSS / JavaScript | High-performance web charts, WebGL rendering for large dataset visualization, 20+ chart types, rich interaction model, excellent mobile support | Yes (Apache 2.0) | Excellent performance for large dataset rendering via WebGL; very popular in Asia with growing Western adoption; open-source with commercial-quality polish; good mapping support | Less community support in English-language ecosystems; configuration can be verbose; less suited for data scientists compared to Plotly; UI customization requires deep knowledge |
| Highcharts | Highsoft | Commercial / Free (non-commercial) | Commercial web charting, 60+ chart types, accessibility compliance (WCAG 2.1), financial chart series, stock charts, Gantt charts, maps included | Partial (non-commercial free) | Most polished commercial chart library; strongest accessibility compliance in the market; financial series and stock charts built-in; excellent documentation | Commercial license required for business use; less flexible than D3 for truly custom charts; premium pricing for enterprise licenses |
| Streamlit | Snowflake | OSS / Cloud | Python-native data apps, rapid prototyping with minimal code, Snowflake Streamlit-in-Snowflake integration, interactive widgets, chart component ecosystem | Yes (Apache 2.0) | Fastest path from Python analysis to shareable interactive app; Snowflake-native deployment reduces infrastructure; very popular in ML and data science community; minimal frontend knowledge needed | Not suitable for complex multi-page enterprise dashboards; acquired by Snowflake creates potential ecosystem questions; performance limits for very large data volumes |
| Flourish | Canva (Flourish) | Cloud (SaaS) | Template-based animated visualizations, data story templates, non-developer friendly editor, responsive output, embed and publish workflow, scrollytelling | No | Best for communications and journalism teams; stunning templates require minimal technical skill; animated charts and stories highly engaging; Canva acquisition adds design resources | Very limited customization beyond templates; not suitable for data exploration or analytical use cases; no programmatic API; primarily a communication tool |
| Datawrapper | Datawrapper | Cloud (SaaS) | News-quality charts and maps, fully responsive output, accessible by default, direct Google Sheets and CSV import, choropleth maps, locator maps | No | Standard in newsrooms and public sector; production-ready responsive charts with minimal configuration; excellent accessibility compliance; clean output suitable for web publication | Very limited chart types beyond standard editorial visualizations; not suitable for complex analytical dashboards; no programmatic generation capability |
| Observable / Observable Framework | Observable | Cloud / OSS | Reactive JavaScript notebooks for data exploration, D3 integration, Observable Framework for building and publishing data sites and reports | Yes (ISC for Framework) | D3 creator's platform; reactive notebooks excellent for data exploration and sharing; Observable Framework enables building production data sites with JavaScript; modern architecture | Requires JavaScript expertise for full capability; niche adoption versus Python-dominant data science tooling; Observable notebooks less widely known than Jupyter |
The BI market is in its most significant transformation since the self-service revolution of the early 2010s. AI-powered natural language querying is reducing the barrier to data access for business users, and ThoughtSpot Sage, Power BI Copilot, and Tableau Pulse represent genuinely mature implementations. Clarista takes this further as a purpose-built AI-native tool specifically designed around making analytics accessible to every business user, not just trained analysts, which represents an important direction for the market.
The semantic layer is re-emerging as a critical architectural component, ensuring consistent metric definitions across tools and preventing the classic problem of different teams calculating revenue differently. Looker LookML, dbt Semantic Layer, and Cube.dev are all approaches to this problem. The most important emerging shift is from reactive to proactive analytics: systems that push relevant insights to users based on what changed, rather than waiting for a user to run a query. Tableau Pulse and ThoughtSpot SpotIQ are the current leaders in this direction. For custom and embedded visualization, the combination of Streamlit or Dash for analytical applications and D3.js or ECharts for custom web charts covers the majority of production use cases.
2.7 ML Platforms and MLOps
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Databricks MLflow + Mosaic AI | Databricks / MLflow (OSS) | OSS / Cloud | Experiment tracking, model registry, serving, AutoML, Feature Store, Unity Catalog AI asset governance, LLM fine-tuning, DBRX model | Yes (MLflow Apache 2.0) | MLflow is the de facto OSS standard for experiment tracking; Databricks adds enterprise management, AutoML, and unified AI asset governance; strong for teams wanting ML and LLM in one platform | Best value inside Databricks platform; MLflow standalone less compelling than Weights and Biases for experiment tracking depth; Mosaic AI LLM fine-tuning cost at scale |
| AWS SageMaker | AWS | Cloud (AWS) | End-to-end managed ML, SageMaker Studio IDE, AutoML (Autopilot), Pipelines for MLOps, Model Monitor, Feature Store, JumpStart for foundation model access | No | Comprehensive managed ML on AWS; SageMaker Studio modernizes the development experience; JumpStart provides pre-built access to foundation models; deep AWS ecosystem integration | Best value inside AWS; less compelling for multi-cloud ML; Studio UX still maturing; operational complexity for self-managed infrastructure within SageMaker |
| Google Vertex AI | Cloud (GCP) | Unified ML platform, AutoML, Model Garden (foundation models), Vertex Pipelines, Feature Store, Model Registry, Gemini integration, TPU access | No | Deep Google Research integration; best access to Google foundation models including Gemini; strong AutoML; TPU access differentiates for large model training workloads | GCP-centric; cross-cloud ML lifecycle management requires additional tooling; Vertex pipelines learning curve; best value for Gemini-centric AI strategy | |
| Azure Machine Learning | Microsoft | Cloud (Azure) | Enterprise MLOps, Designer visual authoring, AutoML, Responsible AI toolkit (fairness, explainability, error analysis), Azure OpenAI integration, Prompt Flow for LLM apps | No | Strong enterprise MLOps; Responsible AI toolkit is best-in-class across cloud providers; Prompt Flow integrates LLM and ML development; Azure OpenAI integration seamless | Azure-centric; Prompt Flow less widely adopted than LangChain for LLM orchestration; operational complexity at scale |
| Weights and Biases | Weights and Biases | Cloud (SaaS) | Experiment tracking, hyperparameter sweeps, model registry, artefact versioning, LLM tracing (Weave), LLM evaluation, collaborative model analysis | No | Best-in-class experiment tracking with 100k+ users; Weave is emerging as the LLM tracing and evaluation standard; excellent collaboration features; integrates with all major ML frameworks | Primarily a tracking and evaluation layer, not a full MLOps platform; serving and deployment require additional tooling; cost at enterprise scale with many users |
| DataRobot | DataRobot | Cloud / On-prem | Automated ML platform, explainability (SHAP), model monitoring, MLOps automation, LLM factory for enterprise LLM deployment, time series AutoML | No | Market leader in enterprise AutoML; broad use case coverage; strong governance and monitoring; LLM factory addresses enterprise LLM deployment governance; good for regulated industries | Premium pricing; best for organizations wanting full MLOps governance automation; less compelling for ML-native engineering teams who prefer hands-on control |
| Hugging Face | Hugging Face | Cloud / OSS | Model Hub (500k+ models), Spaces for hosting ML apps, Inference Endpoints, AutoTrain, Datasets, Transformers library, PEFT for efficient fine-tuning | Yes (multiple OSS) | Hub of the AI community; largest model and dataset repository; central to LLM and ML development ecosystem; Transformers library is the standard; Spaces for sharing ML demos | Hugging Face-hosted inference can be costly for production; Model Hub quality varies widely; requires engineering expertise to deploy models from Hub into production |
| H2O.ai | H2O.ai | OSS / Cloud | AutoML (H2O AutoML and Driverless AI), model interpretability, GPU-accelerated training, H2O Wave app builder, LLM fine-tuning support | Yes (H2O Apache 2.0) | Strong open-source ML heritage; Driverless AI adds automated feature engineering; interpretability features comprehensive; GPU acceleration for faster training; good for regulated industries | Driverless AI commercial product is expensive; community support concentrated around H2O OSS; UI less modern than DataRobot; smaller enterprise footprint |
MLflow has become the OSS standard for experiment tracking and model management, while Weights and Biases leads in research-grade tooling with deeper collaboration features. The cloud hyperscaler platforms (SageMaker, Vertex AI, Azure ML) offer the most comprehensive managed MLOps with the tradeoff of cloud commitment. The most significant 2024–2026 development is the maturation of the LLM application infrastructure: RAG has become the dominant pattern for enterprise AI, and ML platform vendors are adding LLM capabilities (DataRobot LLM Factory, Databricks Mosaic AI, Azure ML Prompt Flow) as a complement to traditional ML lifecycle management.
2.8 LLMs and Generative AI
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Meta Llama (Llama 3.x) | Meta AI | OSS / On-prem / Cloud | Open-weight foundation models (Llama 3.1, 3.2, 3.3), multilingual support, instruction-tuned variants, code generation, multimodal (Llama 3.2 Vision), Llama Stack for deployment | Yes (Meta Llama license) | Largest community of open-weight LLMs; Llama 3.1 405B competitive with closed models; fine-tuning enabled by open weights; Llama Stack provides deployment and toolchain consistency; runs on-premises for data-sovereign deployments | Meta Llama license has some commercial restrictions; large models require significant GPU infrastructure; fine-tuning requires ML expertise; no managed service from Meta directly (requires cloud or self-managed hosting) |
| LangChain / LangGraph | LangChain (OSS) | OSS / Cloud (LangSmith) | LLM orchestration framework, RAG chains, agent tools, memory management, 100+ integrations, LangGraph for stateful multi-agent workflows, LangSmith for observability | Yes (MIT) | Most widely adopted LLM orchestration framework; enormous ecosystem; LangGraph for production-grade stateful agent workflows; LangSmith adds observability and evaluation; very large community | Rapidly evolving API creates breaking changes; abstraction layers can obscure what is actually happening; LangGraph complexity can be significant; best for teams who need broad integration coverage |
| LlamaIndex | LlamaIndex (OSS) | OSS / Cloud | Data framework for LLMs, RAG pipelines over unstructured documents, multi-modal support, query engines, enterprise RAG with evaluation built in, LlamaCloud managed service | Yes (MIT) | Best for data-heavy RAG applications over document corpora; extensive document loader ecosystem; more focused on data grounding than LangChain; LlamaCloud adds enterprise features | Less broad for general agent orchestration than LangChain; rapidly evolving API; LlamaCloud pricing builds on OSS foundation |
| Azure OpenAI Service | Microsoft | Cloud (Azure) | GPT-4o, GPT-4, o1, DALL-E, Whisper, embedding models on Azure; enterprise security with VNET integration; compliance certifications; Copilot Studio; Prompt Flow | No | Enterprise-grade OpenAI model access with compliance and security guarantees; deep Microsoft Copilot and Power Platform integration; very large Azure enterprise customer base | Azure-centric; OpenAI model availability on Azure slightly lags direct OpenAI API; pricing can be higher than direct API at scale; dependent on OpenAI/Microsoft relationship |
| Amazon Bedrock | AWS | Cloud (AWS) | Multi-model foundation model access (Claude, Llama, Titan, Mistral, Cohere), Bedrock Agents for agentic workflows, Knowledge Bases (RAG), Guardrails for safety | No | Multi-model approach reduces lock-in; Bedrock Agents for agentic workflows is production-ready; Guardrails for content safety and hallucination reduction; deep AWS integration | AWS-centric; model selection less comprehensive than Vertex AI Model Garden; Agents complexity can be significant; Guardrails is an important but still maturing capability |
| Google Vertex AI (Gemini) | Cloud (GCP) | Gemini 2.x model family, Vertex AI Studio, RAG engine, Grounding with Google Search, Agent Builder for enterprise agents, 2M token context window | No | Best long-context window models; Gemini 2.0 Flash leads on cost-performance balance; Agent Builder for enterprise agents; Grounding with Search for factual accuracy; deep Google ecosystem | GCP-centric; Agent Builder less mature than AWS Bedrock Agents; Gemini models available outside GCP via API but enterprise features are GCP-native | |
| Anthropic Claude API | Anthropic | Cloud / API / Bedrock | Claude 3.7 Sonnet and Opus, extended thinking mode, computer use for agentic workflows, tool use, 200k context window, Amazon Bedrock and Google Cloud availability | No | Leading reasoning and safety-focused model; extended thinking produces high-quality reasoning for complex tasks; computer use enables novel agentic workflows; 200k context for large document processing; growing enterprise trust | Primarily API access; no model fine-tuning available; computer use in beta with limitations; dependent on Anthropic for ongoing model availability |
| Ollama / vLLM | OSS community | OSS / On-prem | Local LLM inference (Ollama, supports Llama, Mistral, Gemma), high-throughput production LLM serving (vLLM), OpenAI-compatible API, self-hosted deployment | Yes (MIT / Apache 2.0) | Critical for on-premises and air-gapped deployment; vLLM delivers production-grade throughput for self-hosted models; OpenAI-compatible API minimises code changes; completely free | Requires significant GPU infrastructure investment; operational complexity of self-managed model serving; performance tuning requires expertise; no enterprise support unless via commercial distributions |
| Snowflake Cortex AI | Snowflake | Cloud (SaaS) | Foundation model access within Snowflake (Llama, Mistral, Arctic, Jamba), Cortex Search for semantic retrieval over Snowflake data, Cortex Analyst for natural language to SQL, Document AI for structured extraction from documents, LLM inference via SQL functions, no data movement outside Snowflake perimeter | No | Unique zero-data-movement architecture means LLM inference runs directly against data already in Snowflake without API hops or data copies; strong data residency guarantees for regulated industries; no separate AI infrastructure to manage; Cortex Analyst makes natural language querying accessible to business users without building a separate application layer | Model selection is narrower than Bedrock or Vertex AI; less suitable for organizations needing highly customized or fine-tuned models; agentic and multi-step workflow capabilities less mature than Bedrock Agents or LangGraph; best value only for organizations with significant data already in Snowflake; Cortex features vary by cloud region and are not uniformly available across all Snowflake deployments |
| Databricks Mosaic AI | Databricks | Cloud | Foundation model access (DBRX, Llama, Mistral, and others via Model Garden), LLM fine-tuning on proprietary data, model serving at scale, Vector Search for semantic retrieval, AI Playground for experimentation, MLflow for LLM experiment tracking and evaluation, integration with Unity Catalog for AI asset governance | Partial (MLflow, DBRX weights) | Strongest platform-native option for fine-tuning open-weight models on your own data; MLflow provides native LLM tracking and evaluation that most other platforms lack; Vector Search integrates directly with Delta tables eliminating separate vector infrastructure; AI asset governance through Unity Catalog means models and embeddings are governed alongside the data they were built on | Best value for organizations already on Databricks; less compelling as a standalone LLM platform; model serving cost at high inference volumes can be significant; broader model selection available through Bedrock or Vertex AI; agentic workflow capabilities less mature than Bedrock Agents |
Meta Llama has fundamentally changed the economics of LLM deployment. Open-weight models that are competitive with closed commercial models give organizations the choice between API-based services (Azure OpenAI, Anthropic, Bedrock) and self-managed deployment (Ollama, vLLM, Databricks Model Serving) that were not viable options two years ago. This is particularly important for data-sovereign requirements in regulated industries, where no data can leave the organizational perimeter. RAG has become the dominant pattern for enterprise AI, with LlamaIndex and LangChain as the primary orchestration frameworks for building document-grounded AI applications over enterprise knowledge bases.
2.9 Agentic AI
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| LangGraph | LangChain (OSS) | OSS / Cloud (LangSmith) | Graph-based stateful multi-agent orchestration, cyclical workflows with conditional routing, persistent memory, human-in-the-loop checkpoints, streaming execution, LangSmith observability | Yes (MIT) | Most production-ready open-source agentic framework; graph model enables complex conditional workflows that simple chains cannot express; persistent state and memory management are essential for long-running agents; human-in-the-loop design enables governance checkpoints; LangSmith provides observability for debugging complex agent traces | Significant complexity for teams new to graph-based programming; rapidly evolving API introduces breaking changes; observability and debugging of complex agent flows requires significant investment; LangSmith adds cost for full observability |
| AWS Bedrock Agents | AWS | Cloud (AWS) | Managed agent orchestration with multi-step reasoning, tool use, Knowledge Bases for RAG grounding, Action Groups for API integration, Agent Supervisor for multi-agent workflows, Guardrails for safety | No | Fully managed agent infrastructure on AWS; Guardrails for safety and content filtering; multi-agent orchestration with Agent Supervisor; Bedrock Knowledge Bases provide grounded RAG; strong enterprise security and audit logging; good for organizations standardised on AWS | AWS-centric; less flexible than open-source frameworks for custom agent architectures; Guardrails safety coverage still maturing; pricing can be significant for high-volume agentic workflows |
| Google Agent Builder / Vertex AI Agents | Cloud (GCP) | Enterprise agent building platform, pre-built agent templates, multi-agent workflows, Grounding with Google Search, Vertex AI integration, Gemini foundation models, Dialogflow CX for conversational agents | No | Strong grounding with live Google Search for factual accuracy; pre-built agents for common enterprise use cases; Gemini long-context window (2M tokens) enables large document processing; Vertex AI integration for ML-enhanced agents | GCP-centric; Agent Builder less mature than AWS Bedrock Agents for complex multi-step workflows; enterprise references still building for production agentic deployments | |
| Microsoft Copilot Studio | Microsoft | Cloud (Azure / M365) | Low-code agent builder, Teams and M365 integration, SharePoint and graph connectors, Power Platform integration, Azure OpenAI backed, Copilot orchestration for Microsoft 365 | No | Best for building agents within Microsoft 365 ecosystem; low-code interface accessible to non-developers; native integration with Teams, SharePoint, Outlook, and Power Platform; strong for automating knowledge worker tasks over Microsoft data | Primarily Microsoft 365 scope; limited flexibility for complex agentic workflows beyond Microsoft data sources; less programmable than LangGraph or Bedrock Agents for engineering teams; Azure OpenAI model dependency |
| Anthropic Claude with Tool Use | Anthropic | Cloud / API | Tool use for structured data retrieval and action execution, computer use for browser and desktop automation, extended thinking for complex multi-step reasoning, 200k context for long-running tasks | No | Best reasoning capability for complex multi-step agent tasks; computer use enables automation of UI-based workflows without APIs; extended thinking produces verifiable reasoning traces; long context enables large document processing within a single agent call | Computer use still in beta with performance variability; no managed agent orchestration framework (requires LangChain, LangGraph, or custom code); fine-tuning not available; cost significant for long reasoning chains |
| AutoGen (Microsoft Research) | Microsoft Research (OSS) | OSS / Python | Multi-agent conversation framework, GroupChat for multi-agent collaboration, AutoGen Studio for low-code agent building, teachable agents with persistent memory, code execution sandboxing | Yes (MIT) | Pioneering multi-agent collaboration research framework; GroupChat enables complex agent team patterns; code execution sandboxing for safe agentic code generation; AutoGen Studio lowers barrier to multi-agent prototyping | Research origin means API stability less prioritized than production frameworks; AutoGen v0.4 rewrite introduced significant changes; less production-proven than LangGraph at enterprise scale; documentation less comprehensive than LangChain |
| CrewAI | CrewAI (OSS) | OSS / Cloud | Role-based multi-agent workflows, crew and task abstractions, sequential and hierarchical process support, tool integration, memory and caching, CrewAI Enterprise for managed deployments | Yes (MIT) | Intuitive role-based abstraction makes multi-agent systems more comprehensible; fast-growing community; good balance of simplicity and capability; CrewAI Enterprise adds managed orchestration and monitoring | Younger project relative to LangGraph; production enterprise references still building; complex state management less mature than LangGraph; Enterprise tier pricing still establishing market position |
| Rivet (Ironclad) | Ironclad (OSS) | OSS / Desktop | Visual node-based agent workflow builder, graph execution for LLM chains and agents, local and cloud execution, debugging and step-through execution, TypeScript API | Yes (MIT) | Best visual tool for designing and debugging complex LLM workflows; node-based model makes agent logic visible and auditable; excellent for teams wanting to prototype and visualise agent architectures | Primarily a design and debugging tool; production deployment requires additional infrastructure; smaller community than LangChain or AutoGen; TypeScript-first limits Python-centric teams |
Agentic AI is moving from proof-of-concept to production faster than most enterprise technology roadmaps anticipated. In data management specifically, agent use cases include automated data quality remediation, data catalog enrichment (agents that generate metadata, classifications, and documentation for new assets), pipeline self-healing, and governed data retrieval (agents that respond to natural language data questions by constructing and executing queries with appropriate access controls applied).
The critical governance challenge for agentic AI is that agents make decisions and take actions autonomously based on data they access. If that data is incorrect, sensitive, or unauthorized, the agent's actions will propagate the problem at a scale and speed no human-driven process would. Organizations deploying production agents should treat agent access to data systems as a first-class governance concern, with agent identities subject to the same access control and audit requirements as human users.
2.10 Content Management
2.10.1 Document Intelligence and IDP
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| ABBYY Vantage | ABBYY | Cloud / On-prem | Intelligent document processing, OCR, form and table extraction, NLP-based field recognition, low-code skill builder, API-first integration, human-in-the-loop review | No | Most mature IDP platform; extensive document type coverage; strong in financial and healthcare sectors; high OCR accuracy on complex layouts; API-first design integrates well with data pipelines | Primarily document preparation focus; does not extend to broader unstructured data governance; integration effort required for data pipeline use; skilled builder needed for complex document types |
| AWS Textract | AWS | Cloud (AWS) | ML-powered OCR, forms extraction, table detection, signature detection, Queries API for targeted field extraction, async processing for large volumes | No | Highly accessible managed service; excellent AWS ecosystem integration; Queries API allows targeted field extraction without full document parsing; pay-per-use pricing; strong for high-volume document pipelines | AWS-centric; table extraction struggles with complex multi-level layouts; limited customization without custom model training; cost scales at very high volume |
| Google Document AI | Cloud (GCP) | Pre-trained processors for invoices, passports, W2s, driving licences, custom processors, Document AI Workbench for model training, batch and online processing | No | Widest range of pre-trained document type processors; deep Google ML capabilities for complex document layouts; Document AI Workbench for custom training; strong for GCP-centric organizations | GCP-centric; pre-trained models may need fine-tuning for organization-specific document variants; pricing higher than Textract for equivalent volumes | |
| Azure AI Document Intelligence | Microsoft | Cloud (Azure) | Layout analysis, prebuilt models (invoice, receipt, ID, W2), custom model training, Document Intelligence Studio, integration with Azure OpenAI for combined extraction and generation | No | Strong integration with Azure OpenAI for combined document extraction and LLM processing; good developer experience; Document Intelligence Studio for model building; HIPAA and compliance ready | Azure-centric; table extraction on complex documents still requires validation; custom model training requires labelled data investment |
| Hyperscience | Hyperscience | Cloud / On-prem | Intelligent document automation, human-in-the-loop validation, structured and semi-structured document processing, ERP integration, SLA-managed processing workflows | No | Strong at high-accuracy, high-value document processing where human review is required; robust human-in-the-loop design reduces errors for critical documents; ERP integration is a differentiator | Higher cost reflects human validation premium; not suitable for purely automated high-volume pipelines where human review is unnecessary; primarily enterprise focus |
| UiPath Document Understanding | UiPath | Cloud / On-prem | IDP integrated with RPA automation, ML extraction models, human validation station, UiPath Automation Cloud integration, pre-trained and custom models | No | Best for organizations combining document processing with robotic process automation workflows; native UiPath integration eliminates separate IDP and RPA platforms; strong automation orchestration | Best value inside UiPath ecosystem; UiPath dependency limits appeal for organizations not using RPA; ML model quality varies across document types |
2.10.2 Enterprise Content Management and Search
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| Microsoft SharePoint / Syntex | Microsoft | Cloud (Microsoft 365) | Document management, content types, metadata extraction via Syntex AI, compliance labels, Power Automate integration, SharePoint Premium AI features, Copilot over documents | No | Dominant enterprise content management; Syntex AI adds automated classification and metadata extraction directly in SharePoint; Microsoft 365 Copilot over documents is powerful; deep compliance integration | Primarily within Microsoft ecosystem; governance complexity at very large scale; SharePoint Premium pricing adds up; search quality across large tenants requires tuning |
| Data Dynamics Zubin | Data Dynamics | Cloud / On-prem | Unstructured data management platform, NAS/S3/SharePoint/file server content management, metadata extraction, retention automation, storage tiering, GDPR and HIPAA compliance for documents | No | Comprehensive unstructured data lifecycle management combining governance, compliance, cost optimisation, and content search; strong for organizations with large NAS and file server estates; real-time analytics over file metadata | Primarily unstructured data focus; structured database governance is not the strength; less well known than SharePoint or OpenText in ECM market; primarily compliance and storage-driven use cases |
| OpenText Content Suite / Documentum | OpenText | On-prem / Cloud | Enterprise content management, records management, archiving, document lifecycle workflows, compliance, OpenText Intelligent Capture for document ingestion | No | Long-established ECM; very strong in regulated industries (pharma, legal, financial); mature records management and compliance capabilities; broad deployment across large enterprises | Legacy architecture limiting agility; modernization to cloud is slower than Microsoft; complex licensing; less compelling for new deployments versus modern cloud-native alternatives |
| Box | Box | Cloud (SaaS) | Cloud content management, Box AI for classification and content extraction and Q&A over documents, metadata templates, Box Sign, secure collaboration, developer APIs | No | Strong enterprise cloud content platform; Box AI adds classification, extraction, and document Q&A natively; excellent API for integration; security and compliance certifications comprehensive | Collaboration focus rather than deep governance; metadata model less powerful than SharePoint for complex content types; ECM workflow depth less than OpenText |
| Coveo | Coveo | Cloud (SaaS) | AI-powered enterprise search across SharePoint/Confluence/Salesforce/web/email, relevance tuning, behavioral analytics, semantic search, customer-facing search integration | No | Best unified search across heterogeneous content repositories; AI relevance model improves continuously with usage; good for customer-facing AI-powered search applications | Primarily a search layer, not a content management platform; governance capabilities limited; pricing significant for large enterprises |
| Elasticsearch / OpenSearch | Elastic / AWS (OSS) | Cloud / OSS | Full-text search across unstructured content, NLP-enhanced semantic search, vector search (kNN), log analytics, multimodal content indexing | Yes (OpenSearch Apache 2.0) | Core infrastructure for unstructured content search; widely deployed for enterprise document retrieval; OpenSearch fully open-source alternative; kNN vector search for semantic retrieval | Not a content management or governance platform; requires engineering to build governance layer; operational complexity at scale; cost can grow quickly with data volume |
2.10.3 Unstructured Data for AI Pipelines
| Tool / Platform | Vendor | Deployment | Key Capabilities | OSS | Strengths | Weaknesses |
|---|---|---|---|---|---|---|
| LlamaIndex | LlamaIndex (OSS) | OSS / Cloud | Document loading from 150+ source types, chunking strategies, indexing, RAG pipeline orchestration, multi-modal support, query engines for unstructured content, agents | Yes (MIT) | Best framework for building RAG systems over document corpora; extensive loader ecosystem for all file types; good chunking strategies for complex documents; multi-modal support growing; active OSS community | Requires Python engineering; rapidly evolving API can break existing implementations; not a managed service with enterprise SLAs; quality of retrieval depends heavily on chunking and embedding choices |
| Unstructured.io | Unstructured | OSS / Cloud API | Universal document parsing for LLM pipelines, partition by file type, layout-aware PDF parsing, chunking strategies, cloud API for enterprise scale processing | Yes (Apache 2.0) | Purpose-built for LLM document preprocessing; layout-aware parsing handles complex PDFs with tables and mixed content; OSS and cloud API versions available; becoming a standard in the LLM pipeline stack | OSS version requires infrastructure; cloud API cost at scale; quality on very complex layouts still imperfect; primarily a preprocessing tool rather than end-to-end pipeline |
| Apache Tika | Apache (OSS) | OSS / Java | Content detection and text extraction from 1000+ file formats, metadata extraction, language detection, MIME type identification | Yes (Apache 2.0) | Universal file format parser; used as a preprocessing step in virtually every enterprise document pipeline; 1000+ supported formats is unmatched; completely free | Java-based adds complexity for Python-centric pipelines; no layout awareness for complex PDFs; minimal NLP processing beyond extraction; requires wrapping for modern LLM pipeline integration |
| spaCy | Explosion AI (OSS) | OSS / Python | Industrial-strength NLP, named entity recognition, dependency parsing, text classification, multi-language support, custom training, production-optimised pipelines | Yes (MIT) | Fastest production NLP library; widely used for entity extraction from documents; excellent multi-language support; prodigy annotation tool for training; very active community | Deep learning models require GPU for best performance; transformer-based spaCy models require more resource; less suitable for generative tasks versus LLMs |
| AWS Bedrock Knowledge Bases | AWS | Cloud (AWS) | Fully managed RAG infrastructure, automatic chunking and embedding generation, S3 and Confluence connectors, semantic retrieval, integration with Bedrock foundation models | No | Minimal infrastructure management for end-to-end document-to-RAG pipeline on AWS; automatic embedding management; good for teams wanting managed RAG without engineering the pipeline stack | AWS-only; limited customization of chunking and retrieval strategies versus LlamaIndex; cost can be opaque; best when committed to AWS Bedrock foundation models |
| Azure AI Search | Microsoft | Cloud (Azure) | Cognitive search with built-in AI enrichment pipeline (OCR, entity extraction, translation, key phrase extraction), vector search, hybrid retrieval, semantic ranking | No | Best managed search with AI enrichment pipeline; strong Azure OpenAI integration for combined extraction and generation in RAG workflows; semantic ranking improves retrieval quality significantly | Azure-centric; vector search at very large scale less proven than Pinecone or Milvus; enrichment pipeline configuration complexity grows with document variety |
Unstructured data management has gone from a niche specialisation to a strategic priority in under three years, driven almost entirely by the LLM application buildout. Every organization building internal AI assistants, contract analysis tools, knowledge bases, or customer-facing AI products needs to process, chunk, embed, and retrieve documents reliably. The tooling stack for this — using Tika or Unstructured.io for parsing, spaCy or LLMs for extraction, LlamaIndex for pipeline orchestration, and a vector database for retrieval — is now as mature as the structured data pipeline stack.
The governance challenge for unstructured data remains less solved. Organizations know how to govern a database table; governing a SharePoint library of 10 million documents with proper ownership, retention, classification, and access control is harder and less standardised. Microsoft Purview, Varonis, Data Dynamics Zubin, Collibra DeasyLabs, and Ohalo address this most directly. This gap will close as regulatory pressure from the EU AI Act (data provenance requirements for AI training data) and financial records regulations forces organizations to extend governance frameworks formally to unstructured assets.
3. Tool Category Overlaps and Platform Convergence
One of the most practical challenges in building a data and AI platform is that the clean category boundaries used to organize tool evaluations rarely match the capabilities of real products. Over the past five years, vendors have systematically expanded into adjacent categories, driven by two forces: a deliberate go-to-market strategy to capture more of the customer's budget in a single contract, and genuine customer demand for integrated functionality that avoids the integration tax of stitching together many point solutions. The result is a landscape where a single platform like Snowflake or Databricks now touches eight or more of the categories described in this paper, and choosing between tools requires understanding not just which tool is best in a single category, but how category overlap changes the build-versus-buy and consolidate-versus-best-of-breed calculus.
3.1 Why Tools Overlap: Vendor Expansion Patterns
Vendor expansion follows several recurring patterns. Data platforms expand horizontally to retain customers and increase average contract value. Snowflake began as a cloud data warehouse but now covers data ingestion (Snowpipe, Dynamic Tables), transformation (Snowpark), data quality (Cortex AI checks), catalog (Horizon Catalog), governance (Horizon policies), marketplace (Data Marketplace), BI (Streamlit-in-Snowflake), and AI tooling (Cortex AI, Snowflake Cortex Search). Databricks has followed a parallel path from a Spark-based lakehouse to a full ML, ETL, governance, and AI platform through Unity Catalog, MLflow, Delta Live Tables, and Mosaic AI.
Governance platforms expand to capture the data product value chain. Collibra began as a business glossary and data catalog but now covers governance workflows, data quality, marketplace, lineage, and is extending to unstructured data governance through DeasyLabs. Alation has extended from catalog into stewardship workflows, data quality certification, and governance programs. Atlan has built a modern catalog with embedded governance, data products, and quality integration.
Integration platforms expand up the value chain toward analytics. MuleSoft has extended from API integration into data integration, analytics (via Tableau), and AI (via Salesforce Einstein). Informatica has expanded from ETL into MDM, data quality, catalog, lineage, and API management under the IDMC umbrella. This convergence means that many enterprises now find themselves with significant functional overlap across their licensed platforms, each having independently expanded into shared territory.
3.2 Platform Capability Overlap Heatmap
The heatmap (Figure 2 in the full report) illustrates how 10 major platforms map across 21 tool categories covered in this paper. A "Primary" designation indicates the platform was built specifically for this category or has a market-leading capability here. A "Partial" designation indicates the platform has meaningful capability in this category, though it may not be the strongest option.
Figure 2 — Platform Capability Overlap Across Tool Categories (Primary / Partial / None)
The heatmap reveals several important patterns. First, Snowflake and Databricks now have meaningful capability across 15 or more of the 21 categories, making them the most horizontally expansive platforms in the landscape. Second, Microsoft Fabric occupies a similar position for Microsoft-committed organizations, with particular strength in the unstructured data and governance categories that reflect Microsoft's M365 heritage. Third, specialist governance vendors (Collibra, Atlan, Informatica) show "Primary" ratings concentrated in the upper portion of the stack (catalog, lineage, governance, quality) but limited presence in infrastructure categories. Fourth, pure infrastructure tools (AWS, Kafka, Airflow) are deep in specific categories but narrow overall.
3.3 Categories with the Most Overlap
Data cataloging and discovery attract the most overlap, with cloud platforms (Snowflake Horizon, Databricks Unity Catalog, Google Dataplex, Microsoft Purview), specialist catalog vendors (Collibra, Alation, Atlan, DataHub), and data quality platforms all claiming catalog capabilities. For most enterprises, the right answer is a primary catalog for governed metadata combined with cloud-native catalogs for platform-specific assets, integrated via open metadata standards like OpenMetadata or DCAT.
Data quality and observability is similarly crowded. Cloud platforms (Glue DQ, Dataplex DQ, Snowflake DQ, Databricks Lakehouse Monitoring), transformation tools (dbt Tests), and dedicated observability platforms (Monte Carlo, Soda, Great Expectations) all provide quality capabilities. Enterprises often layer these: cloud-native checks for in-platform workloads, dbt Tests for ELT transforms, and a centralised observability platform for cross-platform anomaly detection.
Data governance is expanding in both directions: upward into AI governance (Collibra AI governance module, Microsoft Purview AI governance) and outward into unstructured data (Collibra DeasyLabs, Microsoft Purview, BigID). The governance category is probably the one where best-of-breed remains most defensible against platform consolidation, because governance depth and maturity of stewardship workflows still significantly differentiates specialist vendors from platform bolt-ons.
3.4 Strategic Implications for Tool Selection
Overlap awareness should inform platform selection in several ways. When evaluating a new tool, assess whether existing platform investments already cover 60–70% of the requirement before licensing a new specialist tool. The total cost of the integration tax on a new point tool (connectors, testing, data movement, security review, training) often exceeds the incremental value over an adequate platform native capability.
Reserve best-of-breed selection for categories where depth genuinely matters and where the gap between platform-native and specialist capability is commercially significant. Deep governance workflows (Collibra), financial reconciliation (AutoRek, Gresham), specialist financial MDM (GoldenSource, Markit EDM), high-accuracy document processing (ABBYY), and advanced AI governance (Credo AI, Fiddler) are examples where specialist tools remain clearly superior to platform bolt-ons for organizations with significant requirements in those areas.
Use open standards to manage overlap. Apache Iceberg for storage, OpenLineage for lineage, OpenMetadata for catalog metadata exchange, and DCAT for open data all reduce the cost of multi-platform architectures by enabling interoperability. Platforms that support these standards can coexist with appropriate division of responsibility; platforms that resist open standards create problematic lock-in as their scope expands.
4. The Future Landscape: Impact of AI and Agentic AI
The data and AI tools landscape is entering its most disruptive period since the cloud revolution of the early 2010s. Large language models, multimodal foundation models, and agentic AI systems are reshaping how data is managed, governed, and used. This section offers a structured forward-looking analysis across key dimensions of transformation.
4.1 The Transition to Real-Time Data
One of the most significant architectural shifts underway is the move from batch-oriented data processing to real-time and near-real-time data availability. This transition is driven by business demands for operational analytics, personalised customer experiences, real-time fraud detection, and autonomous AI decision-making, all of which require data that reflects the current state of the world rather than yesterday's batch load.
Real-time data architecture affects every category covered in this paper. In ingestion, Change Data Capture (CDC) and event streaming tools (Debezium, Kafka, Kinesis) are displacing batch ETL for transactional data. Snowflake Dynamic Tables and Databricks Delta Live Tables now enable near-real-time materialised views that automatically propagate changes from source systems without manual pipeline engineering. Google BigQuery Storage Write API supports sub-minute data availability in BigQuery, eliminating the overnight ETL cycle for analytics.
In transformation and quality, the paradigm is shifting from running dbt jobs on a schedule to continuous or triggered transformation where new data arriving triggers downstream model refreshes automatically. Data quality checks must evolve from batch validation to continuous stream-level monitoring, which is driving the convergence of data quality tools (Soda, Great Expectations) with stream processing frameworks (Flink, Spark Streaming).
In governance, real-time data presents new challenges. Policies governing PII must be enforced at write time, not just at query time. Lineage must be traceable at event level for regulatory obligations such as BCBS239 intraday risk reporting and MiFID II trade reporting. Access control decisions that were previously made in batch policy scans must operate at millisecond latency to support real-time data access. Tools like Immuta and Privacera are investing in real-time policy enforcement capabilities to address this.
The tooling implications are significant. Reconciliation platforms (AutoRek, Gresham Clareti) are adding intraday reconciliation that runs every few minutes rather than at end of day. Observability platforms (Monte Carlo, Bigeye) are adding streaming data source support. BI tools are adding direct streaming data sources alongside warehouse queries. The net effect is that organizations maintaining separate batch and streaming data pipelines will increasingly converge these onto unified platforms, with Snowflake, Databricks, Kafka-native platforms, and Apache Flink as the primary architectural choices for unified batch and streaming processing.
4.2 The Agentic AI Paradigm
Agentic AI refers to systems that can pursue multi-step goals autonomously, using tools, accessing data, making decisions, and taking actions without requiring human instruction at each step. Unlike traditional AI models that respond to single prompts, agents maintain state across interactions, decompose complex goals into executable plans, and use specialised tools including data query engines, API connectors, code execution environments, and memory stores.
The emergence of reliable agentic frameworks (LangGraph, AWS Bedrock Agents, Google Agent Builder, Anthropic Claude with computer use, Microsoft Copilot Studio) in 2024–2025 is moving agentic AI from experimental to production. The implications for data tooling are profound: categories of tools that today require human-driven workflows are candidates for agent-driven automation, and the pace of change is faster than most enterprise technology roadmaps have planned for.
4.3 Category-by-Category Transformation
Data Discovery and Cataloging: Natural language search over data catalogs will evolve into conversational data exploration where agents proactively surface relevant datasets, explain their provenance, and assess their quality in response to business questions. Automated metadata generation using LLMs will eliminate the manual curation burden that has historically limited catalog completeness.
Data Preparation and Transformation: AI-assisted data preparation is already transforming the category. The next phase involves fully autonomous preparation agents that receive a business objective, identify relevant sources across both structured and unstructured data, assess quality, propose and execute transforms, and produce a documented, tested output dataset.
Data Quality and Observability: ML-based anomaly detection will be augmented by LLM-powered root cause analysis that explains quality issues in business terms rather than technical metrics. Agents will initiate remediation actions autonomously: re-running failed pipeline segments, triggering data steward notifications, applying known-good correction rules.
Data Governance and Lineage: Policy authoring, currently a labour-intensive human process, will be AI-assisted, with LLMs translating regulatory text (GDPR Article 25, EU AI Act Article 10) directly into executable data policies. Automated lineage tracking will become comprehensive through AI agents monitoring code changes, query patterns, and API calls to construct real-time lineage graphs without manual annotation.
Pipeline Orchestration: Future pipeline orchestration will be declarative and AI-driven. Rather than writing Airflow DAGs or Dagster asset definitions manually, engineers will describe desired data products and their business requirements, with AI systems generating, optimising, and maintaining the underlying pipeline code. Self-healing pipelines, where orchestration agents detect failures, diagnose root causes, and apply fixes autonomously, will become standard for mission-critical infrastructure.
Business Intelligence and Analytics: The conversational BI paradigm, where users ask questions in natural language and receive accurate contextually-aware answers, will achieve reliable accuracy through advances in text-to-SQL grounded in semantic layers and retrieval-augmented generation over structured data. The tools heading in this direction (ThoughtSpot Sage, Power BI Copilot, Clarista, Looker with Gemini) represent early but increasingly production-ready versions of this vision.
4.4 Emerging Architectural Patterns
The AI Data Stack and Real-Time Integration: A new architectural layer is emerging specifically to support AI applications: vector databases for semantic search, embedding management pipelines, RAG infrastructure, and LLM gateway and routing layers. This AI data stack sits alongside, and increasingly integrates with, the traditional analytical data stack. The real-time dimension adds further complexity: AI applications increasingly need real-time data feeds, requiring streaming ingestion pipelines that feed both analytical stores and AI retrieval systems simultaneously. Unified streaming-and-batch platforms (Databricks, Snowflake Dynamic Tables, Apache Flink) are becoming the foundation layer that serves both analytical and AI data needs in a single architecture.
Data Mesh and AI Agents: The Data Mesh paradigm, distributing data ownership to domain teams that publish governed data products, creates an ideal substrate for AI agent operation. Domain agents can maintain their own data products, respond to quality incidents, and answer business questions within their domain boundaries. A federated agent network, coordinated by a central orchestration layer, can serve cross-domain analytical needs by composing responses from domain-specific agents.
Synthetic Data as a First-Class Asset: The combination of generative AI with data management creates synthetic data as an important new asset class. For use cases where privacy constraints limit real data availability (healthcare, financial services, PII-rich datasets), AI-generated synthetic data that is statistically representative but contains no real individual records becomes critical infrastructure for ML training and testing. Tools like Mostly AI, Gretel.ai, and Tonic.ai are pioneering this space.
Autonomous Data Contracts: Data contracts — formal agreements between data producers and consumers defining schema, quality guarantees, and SLAs — are gaining traction as an architectural pattern. AI will automate the monitoring and enforcement of data contracts: detecting schema violations, calculating quality SLA breach metrics automatically, and routing incident notifications to responsible owners.
4.5 Platform Consolidation vs. Best-of-Breed
The tool landscape will continue along two parallel tracks. Major platforms (Snowflake, Databricks, Microsoft Fabric, Google BigQuery with Vertex AI, and AWS) will continue horizontal expansion, absorbing adjacent tool categories through acquisition or organic development, offering integrated platforms covering the full data-to-AI lifecycle. For many organizations, this platform-centric approach reduces integration complexity and total cost of ownership.
In parallel, a vibrant ecosystem of specialised tools will persist for capabilities where depth matters more than breadth: sophisticated data governance (Collibra), enterprise MDM (Informatica, Reltio), financial reconciliation (AutoRek, Gresham), complex event streaming (Confluent), unstructured data processing (ABBYY, Unstructured.io), and specialist AI governance (Credo AI, Fiddler). The open-source community, particularly around Soda Core, dbt, Airflow, Dagster, DataHub, Great Expectations, and OpenLineage, will continue to define standards and reference implementations that constrain vendor lock-in.
4.6 Summary Outlook
The 2026–2030 data and AI tools landscape will be defined by five forces: platform consolidation reducing the number of tools required for end-to-end data management; AI-native capabilities embedded across all categories eliminating manual overhead; agentic AI automating complex multi-step data workflows; open standards (Iceberg, OpenLineage, OpenMetadata) preventing monopolisation of the stack; and AI governance maturing from reactive monitoring to proactive risk management embedded in the development lifecycle.
The real-time transition — moving from overnight batch to continuous and event-driven data availability — underpins all of these forces and represents perhaps the most significant infrastructure challenge for enterprises in the near term. Unstructured data management, long the poor cousin of structured data tooling, will be a central battleground as organizations try to govern, quality-assure, and extract value from the 80–90% of their data estate that lives outside databases.
5. Conclusions and Strategic Recommendations
This research paper has surveyed more than 30 categories of data management and governance tools, covering over 300 commercial and open-source products. The following recommendations summarise the key insights for enterprise data and technology leaders.
No amount of analytical tooling or AI investment delivers sustainable value without reliable governance foundations: a business glossary with clear data ownership, column-level lineage across the analytical estate, automated PII classification, and data quality monitoring. These investments create the metadata infrastructure that AI systems will increasingly depend on to operate reliably. This governance must extend to unstructured data. Governing only the structured database layer while leaving 80% of the data estate ungoverned creates risks that become very visible as AI systems are built over that ungoverned content.
Build around open standards: Apache Iceberg for analytics storage, OpenLineage for lineage, OpenMetadata for metadata exchange, DCAT for catalog interoperability, and dbt for transformation definitions. These standards enable multi-engine interoperability and provide negotiating leverage with cloud platform vendors. The OpenLineage standard's planned extension to unstructured data and AI pipeline lineage will become important as AI workloads grow, and adopting it early reduces future migration cost.
Select one primary cloud data platform (Snowflake, Databricks, or Microsoft Fabric for most enterprises) to anchor analytics and AI infrastructure. Augment with best-of-breed tools only where the primary platform is genuinely inadequate, typically in deep governance (Collibra), enterprise MDM (Informatica, Reltio), financial data management (GoldenSource, Gresham Alveo, Markit EDM), financial reconciliation (AutoRek, Gresham Clareti), unstructured data processing (ABBYY, Unstructured.io), or specialist AI governance (Credo AI, Fiddler). A 30-tool data stack creates integration complexity that compounds exponentially.
Extend the same data management discipline (cataloging, governance, quality monitoring, and security) to unstructured data that has been applied to structured databases for decades. Start with the highest-risk unstructured assets: contracts, customer communications, regulated records, and AI training data. Microsoft Purview, Varonis, BigID, Data Dynamics Zubin, Collibra DeasyLabs, Ohalo, ABBYY, and Unstructured.io provide the capabilities to get unstructured data under management without building custom infrastructure.
Implement data quality as code, embedded in CI/CD pipelines, with automated regression testing (Datafold), declarative validation (Soda, Great Expectations), and ML-based observability (Monte Carlo, Bigeye). Soda in particular deserves consideration as a primary DQ tool for its combination of developer accessibility, business-user readability of SodaCL, data contract support, and strong OSS community. Extend quality monitoring to AI pipeline outputs using LLM observability tools (Arize Phoenix, WhyLabs) for the generative AI workload layer.
The transition from batch to real-time data availability is no longer optional for competitive operations. Evaluate Snowflake Dynamic Tables, Databricks Delta Live Tables, and Apache Flink as candidates for unified batch-and-streaming architecture. Ensure reconciliation, governance, access control, and quality monitoring tooling is capable of operating at real-time cadence, as end-of-day batch processes are increasingly insufficient for intraday operational and regulatory requirements.
Design data architecture to be agent-ready: structured semantic layers (dbt Semantic Layer, LookML), comprehensive metadata in a central catalog (Atlan, DataHub), governed APIs over all data products, and fine-grained access control evaluable in milliseconds. These investments pay dividends as agentic AI systems begin to operate autonomously across data estates within the next two to three years. Organizations that defer this work will find that AI systems amplify existing governance and quality problems rather than solving them.
Do not treat AI governance as a post-deployment concern. Implement model cards, risk assessments (Credo AI, Holistic AI), bias testing (Microsoft RAI Toolkit, Fiddler), prompt injection protection (Lakera Guard), and continuous monitoring (Arize AI, WhyLabs) as standard deployment gates. With EU AI Act enforcement approaching, organizations without formal AI governance programs face significant regulatory and reputational risk. The traceability requirements of the EU AI Act, including data provenance for AI training data, make the connection between AI governance and data governance tighter than most organizations have yet recognised.
Data infrastructure is becoming AI infrastructure. The same platforms, governance frameworks, and quality standards that enable trustworthy analytics are the prerequisite foundations for trustworthy AI. Organizations that understand this convergence and invest accordingly will be best positioned to capture the value that AI offers while managing the risks it introduces.
6. References and Sources
The following sources were used in the research, analysis, and writing of this paper. Where original URLs may have changed since publication, links redirect to the respective vendor or organization home pages.
6.1 Analyst and Industry Reports
- Gartner Magic Quadrant for Data Integration Tools (2024). Gartner Inc. — gartner.com
- Gartner Magic Quadrant for Augmented Data Quality Solutions (2024). Gartner Inc. — gartner.com
- Gartner Magic Quadrant for Analytics and Business Intelligence Platforms (2024). Gartner Inc. — gartner.com
- Gartner Critical Capabilities for Data Management Solutions for Analytics (2024). Gartner Inc. — gartner.com
- Forrester Wave: Data Governance Solutions, Q1 2024. Forrester Research. — forrester.com
- Forrester Wave: Machine Learning Data Catalog, 2024. Forrester Research. — forrester.com
- IDC MarketScape: Worldwide Data Catalog 2024 Vendor Assessment. IDC. — idc.com
- The Data and AI Landscape 2025. Matt Turck / FirstMark Capital. — mattturck.com
- State of Data Engineering 2025. Airbyte / dbt Labs Annual Survey. — airbyte.com
- 2025 State of Data Quality. Soda / DataKitchen. — soda.io
6.2 Regulatory and Standards Documents
- Regulation (EU) 2016/679 — General Data Protection Regulation (GDPR). Official Journal of the European Union. — eur-lex.europa.eu
- Regulation (EU) 2024/1689 — Artificial Intelligence Act (EU AI Act). European Parliament. — eur-lex.europa.eu
- Digital Operational Resilience Act (DORA) — Regulation (EU) 2022/2554. European Parliament and Council. — eur-lex.europa.eu
- BCBS 239 — Principles for effective risk data aggregation and risk reporting. Basel Committee on Banking Supervision, January 2013. — bis.org
- ISO/IEC 42001:2023 — Artificial Intelligence Management System. International Organization for Standardisation. — iso.org
- NIST AI Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology, January 2023. — nist.gov
- DCAT — Data Catalog Vocabulary (Version 3). W3C Recommendation. — w3.org
- OpenLineage Specification. OpenLineage Community. — openlineage.io
- Apache Iceberg Table Format Specification. Apache Software Foundation. — iceberg.apache.org
6.3 Vendor Documentation and Product Pages
- Snowflake Documentation — docs.snowflake.com
- Databricks Documentation — docs.databricks.com
- Microsoft Fabric Documentation — learn.microsoft.com
- Microsoft Purview Documentation — learn.microsoft.com
- Google Cloud — BigQuery Documentation — cloud.google.com
- Google Cloud — Vertex AI Documentation — cloud.google.com
- AWS — Amazon Bedrock Documentation — docs.aws.amazon.com
- AWS — Amazon SageMaker Documentation — docs.aws.amazon.com
- Collibra Product Documentation — collibra.com
- Atlan Documentation — atlan.com
- Alation Documentation — alation.com
- Apache Airflow Documentation — airflow.apache.org
- dbt Documentation and Best Practices — docs.getdbt.com
- Apache Kafka Documentation — kafka.apache.org
- Confluent Documentation — docs.confluent.io
- Fivetran Documentation — fivetran.com
- Airbyte Documentation — airbyte.com
- Monte Carlo Documentation — montecarlodata.com
- Soda Documentation — docs.soda.io
- Great Expectations Documentation — greatexpectations.io
- Informatica IDMC Documentation — informatica.com
- Denodo Platform Documentation — denodo.com
- Immuta Documentation — immuta.com
- BigID Documentation — bigid.com
- Varonis Documentation — varonis.com
- Fiddler AI Documentation — fiddler.ai
- Arize AI Documentation — arize.com
- Credo AI Platform Documentation — credo.ai
- Lakera Guard Documentation — lakera.ai
- LangChain Documentation — langchain.com
- LlamaIndex Documentation — llamaindex.ai
- Hugging Face Documentation — huggingface.co
- Anthropic Claude API Documentation — anthropic.com
- Meta Llama Documentation — llama.meta.com
6.4 Open Source Projects and Community Resources
- DataHub — Open-Source Data Catalog — datahubproject.io
- OpenMetadata — Open Standard for Metadata Management — open-metadata.org
- Apache Atlas — Data Governance and Metadata Framework — atlas.apache.org
- Apache Ranger — Data Security Framework — ranger.apache.org
- Apache Flink — Stateful Stream Processing — flink.apache.org
- Apache Spark — Unified Analytics Engine — spark.apache.org
- Delta Lake — Open Table Format — Linux Foundation — delta.io
- Apache Hudi — Data Lake Transactions — hudi.apache.org
- Dagster Documentation — dagster.io
- Prefect Documentation — prefect.io
- MLflow Documentation — mlflow.org
- Weights and Biases Documentation — wandb.ai
- whylogs Documentation — whylabs.ai
- Arize Phoenix (OSS) Documentation — arize.com
- spaCy Documentation — spacy.io
- LangGraph Documentation — langchain.com
- AutoGen (Microsoft Research) — microsoft.github.io/autogen
- CrewAI Documentation — crewai.com
- Unstructured.io Documentation — unstructured.io
- Apache Tika Documentation — tika.apache.org
6.5 Academic and Technical Publications
- Zaharia, M. et al. (2016). Apache Spark: A Unified Engine for Big Data Processing. Communications of the ACM, 59(11), 56–65.
- Olston, C. et al. (2011). Pig Latin: A Not-So-Foreign Language for Data Processing. Proceedings of the ACM SIGMOD International Conference on Management of Data.
- Armbrust, M. et al. (2021). Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. Proceedings of CIDR 2021.
- Lewis, P. et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NeurIPS 2020). — arxiv.org/abs/2005.11401
- Touvron, H. et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv. — arxiv.org/abs/2307.09288
- Dehghani, Z. (2022). Data Mesh: Delivering Data-Driven Value at Scale. O'Reilly Media.
- Reis, J. and Housley, M. (2022). Fundamentals of Data Engineering. O'Reilly Media.
- European Commission (2021). Proposal for a Regulation on a European Approach for Artificial Intelligence. COM(2021) 206 final. — eur-lex.europa.eu
